Database의 역활
데이터베이스(DataBase)는 데이터를 효율적으로 저장하고 관리하며, 여러 사용자 또는 Software / Application에서 데이터를 공유하고 접근할 수 있는 시스템입니다. 쉽게 말해서 삭제 및 변경이 가능한 자료의 모음입니다.
데이터베이스(DataBase)는 구조화되어 효율적으로 많은 양의 데이터를 저장하고 관리하면서 데이터를 복구하는 방법을 기본적으로 제공하게 되는데요. 이는 하드웨어 오류로 인하여 데이터 유실에 대응하기 위해 기초적으로 복제하는 것이 첫 번째 방법이 될 수 있습니다.
🟢본 글에서는 아래의 포인트를 가지고 읽기를 권장합니다.
- RDBMS 와 NoSQL 다른점
- 인프라 환경에서 DataBases 역활
- 리플리케이션 (Replication) 개념
- 리플리케이션 관점에서 RDBMS 와 NoSQL
관계형 데이터베이스 vs 비관계형 데이터베이스
관계형 DB와 비 관계형 DB는 데이터 저장 방식으로 구분할 수 있습니다. MySQL의 경우 데이터를 행(Row)과 열(Column)이 있는 테이블 형식으로 저장하게 되며, 열(Column)에는 데이터 속성이 포함되고 행(Row)에는 데이터 값을 넣게 됩니다. Join 절을 사용하여 테이블을 연결하고 다양한 데이터 간 하나의 결과를 보여줄 수도 있습니다.
비 관계형DB의 경우는 스키마가 없는 데이터를 관리하고 저장하며 저장하는 방식이 다양하기 때문에, 관계형 데이터베이스에서 요구되는 제약 조건 없이 저장되는 데이터라고 볼 수 있습니다.
아래의 제시된 예시에 따라 관계형과 비 관계형 데이터베이스의 종류를 알아보도록 하겠습니다.
[1] Relational Database, RDB
- 관계형 모델은 실제 세계의 데이터를 수학적 논리 관계 개념을 사용하여 행(row)과 열(column)로 표현한 표(table)와 행(row)과 열(column)의 상관 관계로 정의하는 데이터 모델입니다.

[2] 키 값 데이터베이스
- 데이터를 Key-Value Pair 형태로 저장되며, 여기서 Key는 고유 식별자 역활을 합니다.

[2] 도큐먼트 데이터베이스
- 개발자가 애플리케이션 코드에서 사용하는 동일한 형식을 말하며, JSON 객체로 데이터를 저장하게 됩니다.
{
company_name: "AnyCompany",
address: {street: "1212 Main Street", city: "Anytown"},
phone_number: "1-800-555-0101",
industry: ["food processing", "appliances"]
type: "private",
number_of_employees: 987
}[3] 그래프 데이터베이스
- 관계를 저장하고 탐색하는 데이터베이스이며, 노드를 사용하여 데이터 엔티티를 저장하며, 엣지로 엔터티 간의 관계를 저장합니다.
인프라에서 DB에서의 역활
데이터 인프라는 조직에서 데이터를 생성, 관리, 보호하는 기반을 제공하며 기본적으로 데이터 중심 결정에 도움이 되도록 적절한 사용자 또는 시스템이 적시에 적절한 데이터를 사용하도록 보장하는 것을 말합니다. 이를 위해 데이터 흐름을 유지하고, 데이터 품질을 보호하며, 중복 데이터를 최소화하고 핵심 데이터 사일로(Data Silos) 격리 방지를 위해 견고한 인프라에서 DB 운영전략을 세워야 합니다. 따라서 데이터의 목적에 따라 데이터 베이스 유형을 정하고, 보호할 수 있도록 적절한 복제 전략이 필요합니다.
* 데이터 사일로 현상 : 조직 내에서 데이터가 서로 분리되어 다른 부서나 시스템에서 액세스할 수 없는 상태 (관련글 보기 ↗)
리플리케이션의 정의와 역활
데이터베이스 리플리케이션은 실시간 복제 데이터베이스 서버를 운용하는 것을 의미하며, 메인(Main)이 되는 서버를 마스터(Master)서버라고 말합니다. Master 서버와 동일한 내용을 갖는 또 다른 서버를 Replica 혹은 Slave라 지칭합니다. 리플리카(Replica)서버는 거의 실시간으로 마스터 (Master)서버와 동일한 데이터를 가지고 있습니다. 데이터베이스에 SQL명령을 보내 데이터 삽입,변경,삭제하게 되는데 마스터(Master)서버는 SQL명령을 수신하면 그 SQL명령을 리플리카(Replica)서버에도 똑같이 보내게 됩니다. 최종적으로는 마스터(Master) 서버와 리플리카(Replica)서버의 데이터가 동일한 상태로 유지됩니다.
리플리케이션을 어떻게 사용할 것인가
데이터베이스 리플리케이션은 데이터가 손상되었을 때, 대처할 수 있는 방안은 가장 최신의 백업(Backup)본을 복구하여 사용하는 것입니다. 단, 백업된 시간과 장애가 발생한 시간 사이에 데이터 변경 사항은 모두 소실되며, 리플리카(Replica)서버는 거의 실시간으로 마스터(Master) 서버와 동일한 데이터를 갖고 있기 때문에 장애 복구 시 데이터 소실이 최소화되며, 리플리카 서버는 마스터 (Master) 서버로 승격이 가능하고 장애 복구 시 마스터(Master)서버에 대한 리플리카(Replica) 서버를 생성하면 복구가 완료됩니다.
MySQL의 Replication과 Elastic Replication
MySQL Replication
MySQL의 복제의 경우 기본적으로 비동기식입니다. 소스의 바이너리 로그에서 이벤트를 복제하는데에 기반하며, 로그 파일과 그 안의 위치를 동기화하는 방식으로 되어 있습니다. 복제의 자체가 동기화를 자동으로 유지하는 과정이므로 Master 와 Slave 은 최종 구성이라고 할 수 있습니다.
위에서 설명한 바와 같이 마스터(Master)의 경우 데이터 등록,수정,삭제 요청 시 BInary-log를 생성하여 Slave 서버로 전달하게 됩니다. Slave의 경우 Master에서 전달받은 바이너리 로그(Binary-logs)를 데이터로 반영하게 됩니다. 사용 목적은 실시간 Data 백업과 여러 대의 DB의 부하 분산입니다.
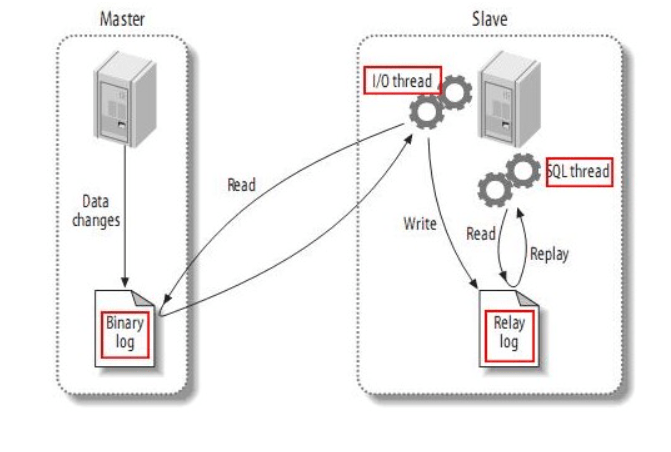
MySQL에서 복제는 바이너리 로그 (Binary-log)파일에 데이터에 대한 모든 변경 사항을 기록하며, 레플리카가 초기화 된다면 2개의 쓰레드(Threads)작업을 생성하게되며, 하나는 I/O 쓰레드( Threads)으로 원본 인스턴스에 연결하고 한 줄씩 바이너리 로그를 읽으며, 레플리카 서버에 Relay 로그에 해당 내용을 복사하게 됩니다. 두 번째 쓰레드는 SQL 쓰레드(Threads)으로, Relay 로그를 읽고 레플리카 DB에 최대한 빠르게 적용하게 됩니다.
Elastic Replication
크로스 클러스터 리플리케이션(Cross-Cluster Replication)은 특정 인덱스를 다른 엘라스틱 클러스터의 리플리케이션(Replication)으로 인덱스(Indexs)레벨에서 , 읽기 전용에서 구성됩니다. 활성 인덱스를 Leader 인덱스로, 수동 읽기 전용 복사본을 Followers 인덱스 라고 합니다.
기본적으로 Remote Cluster ( Replication 의 결과물을 저장하는 Cluster) 설정에서 다른 Elasticseach 클러스터를 연결할 수 있으며, Remote Cluster는 각각 다른 데이터 센터가 될 수도 있고, 혹은 지리적 위치 등 여러 환경이 될 수 있습니다.
CCR(Cross-Cluster Replication)을 사용하기 위해서는 Elastic을 사용하는 Local 과 Remote 환경 버전 모두 6.7 버전 이상이여야 하고, 클러스터 간 복제는 사용자가 생성한 인덱스만 복제하도록 설계되어 있으며 System Indices, Index Template, Elastic Index Lifecycle Management , IAM Roles, SnapShots 의 경우에는 수동으로 복제 해야 합니다.
클러스터 간 복제를 사용하면 원격 클러스터의 인덱스에 데이터를 수집할 수 있습니다. 이 Leader index는 Local Cluster에 있는 1개 이상의 Read-Only Followers 인덱스를 복제하게 됩니다.
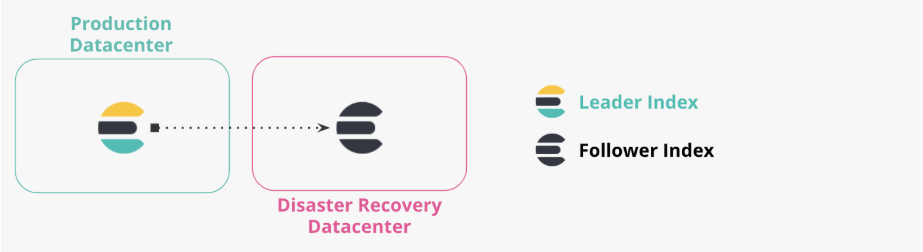
아래에는 CCR의 구조를 엘라스틱 공식 홈페이지에게 발췌하였는데요. 여기서 말하는 DR Datacenter는 Disaster Recovery Data-center 준말이며, 리플리케이션을 통해 데이터를 송신 받는 대상을 말합니다.
- Sample Cross-Datacenter (CCR) Architecture
- Production and DR Datacenter
데이터는 운영 데이터에서 복제 데이터 로 복사되는 모습
- Production and DR Datacenter
2. More Than Two DataCenters
데이터 센터에서 여러 데이터(B,C)으로 복제되는 케이스이며 B,C는 읽기 전용으로 복사됩니다.
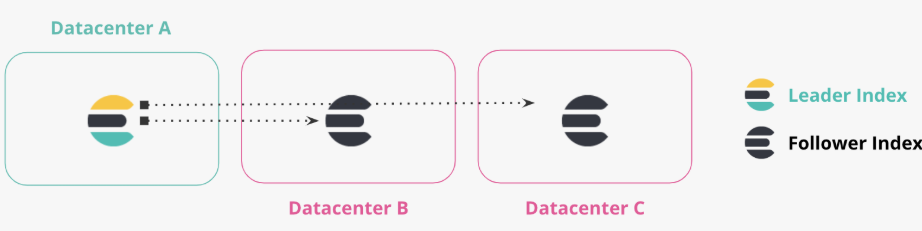
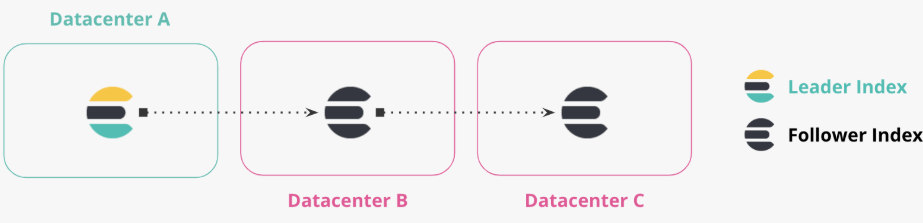
3. Chained Replication
데이터 센터 A에서 데이터 센터 B로 복제 , 데이터 센터 C는 데이터 센터B의 Followers 인덱스에서 복제됩니다.
위와 같이 관계형 DB와 비관계형 DB과, 이에 따른 리플리케이션(Replication)개념과 방법을 알아보는 시간을 가졌습니다. 데이터 중심의 의사 결정 방식에 대한 관심도가 높아짐에 따라 데이터에 보관 방식도 이해도 높아지고 있는데요. 올바른 데이터를 수집하는 것도 중요하지만, 수집한 유효한 데이터를 잘 보관하려고 하는 방법도 중요해 질 것으로 보입니다. 감사합니다.
Ref.
- [[replication] mysql Replication 으로 DB 부하 분산 시키기] https://dgjinsu.tistory.com/51
- [Cross-Datacenter Replication with Elasticsearch Cross-Cluster Replication]https://www.elastic.co/blog/cross-datacenter-replication-with-elasticsearch-cross-cluster-replication
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.