지난 포스트에서는 온라인 서비스에 기본 바탕이 되는 elasticsearch 에 대해서 알아보았는데요,
이번에는 실시간으로 수집된 데이터를 확인할 수 있게 해주는 파이프 라인 도구 “Logstash”에 대해 알아보겠습니다.
먼저 시작하기 전, 오픈소스로 사용되어져 있는 ELK에 대해 아래와 같이 정리해보도록 하겠습니다.
ELK 정의

ELK는 Elasticsearch, Logstash 및 Kibana 의 오픈 소스 프로젝트의 앞 글자를 가져와 만든 단어입니다.
Elasticsearch는 검색 및 분석 엔진이며, Logstash는 데이터를 수집하는 동시에 변환하며 Elasticsearch 같은 “stash”로 전송하는 Server-side 의 Data 처리 Pipeline 역할을 하며, Kibana 는 사용자 Elasticsearch에서 Chart와 Graph를 이용해 데이터를 시각적으로 표현하고 있습니다.
비즈스프링에서는 엘라스틱 서치(Elasticsearch)를 활용하여 빠르게 실시간 데이터를 제공하고 있는데요. 이를 위해서는 로그 파일을 Logstash 로 실시간 인덱싱(indexing)을 해야 데이터를 확인 할 수 있습니다. 이와 관련해서 좀 더 자세히 알아보도록 하겠습니다.
ETL의 정의 -Extract , Transform, Load
ETL은 추출,변환, 로드를 뜻하며 데이터 엔지니어링을 통해 데이터를 추출 , 데이터를 유의미한 리소스로 변환하기 위해 최종 사용자가 액세스하고 가공하여 비즈니스 문제를 해결할 수 있도록 처리하는 과정을 말합니다. 이에 관련된 이전 포스트는 아래 링크를 참고해주세요.
- 참고 콘텐츠 : ETL vs ELT 차이점과 사례 살펴보기
Logstash 의 구성
Elastic 공식 홈페이지에는 Logstash를 아래와 같이 소개하고 있습니다.
Logstash는 서로 다른 소스의 데이터를 탄력적으로 통합하고 사용자가 선택한 목적지로 데이터를 정규화할 수 있다.
Logstash는 다양한 플러그인을 제공할 뿐만 아니라 직접 플러그인을 제공할 수 있으며, 다양한 입력 (input)에 포함되는 데이터와 로그를 가공 (filter)하여 원하는 목적에 업로드(output) 가 가능하도록 만든 도구입니다.
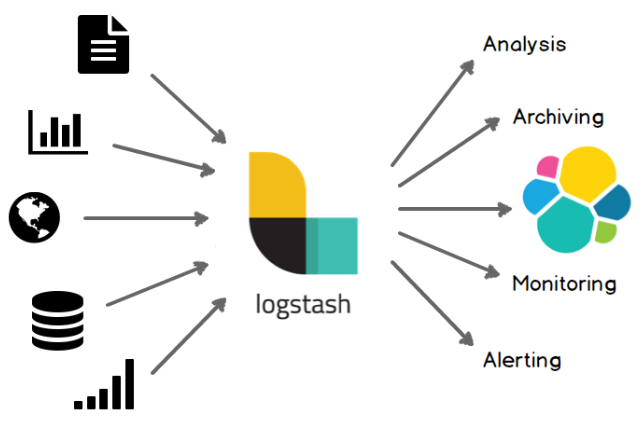
Logstash의 설정(.conf)은 입력(Input), 가공(Filter), 출력(Output) 섹션으로 나뉘는데, 이에 대한 자세한 설명과 동시에 참고 할 수 있는 Plugin들을 정리해보았습니다. Logstash를 활용하여 다양한 로그와 파일을 기반으로 데이터 구조를 구축하고 변환하여 여러가지 결과 값들을 확인할 수 있습니다.
INPUT
Logstash는 데이터를 동적으로 수집, 전환, 전송하여 전반적인 처리를 손쉽게 처리해줍니다. 일반적인 다수의 소스에서 동시에 이벤트를 가져오는 다양한 입력을 지원합니다. Log, Metrics.Web Applications, Data Source 스트리밍 되는 방식으로 수집 할 수 있습니다.
*Input plugin Ref. https://www.elastic.co/guide/en/logstash/current/input-plugins.html
Input plugins 예)
- Files
- SQL Queries
- HTTP requests
- Elasticsearch
- Beats
- Metrics systems
- Logstash pipelines
FILTER
Logstash는 데이터가 이동하는 과정에서 분석과 식별을 통해 구조를 구축하고 이를 바탕으로 변환 통합하여 강력한 분석을 제공합니다. 형식이나 복잡성에 관계 없이 데이터를 동적으로 변환합니다.
*Filter plugin Ref. https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
Filter plugins 예)
- Log Parshing
- Expended Data
- Add tags
OUTPUT
원하는 데이터를 라우팅할 수 있도록 다양한 출력을 제공하며, 이는 Plugins을 통해 확인할 수 있습니다.
*Output plugin Ref. https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Outputs plugins 예)
- Elasticsearch
- Data 보관소 (ex. Amazon S3 , Google storages)
- Alterting & Monitoring System
다양한 출력을 지원하여 여러 저장소로 데이터를 다운스트림 할 수 있으며 ,플러그인 파이프라인 아키텍처를 지향하며 다양한 입력,가공,출력을 조정하면서 조화롭게 운영이 가능합니다
비즈스프링 내에 적용되는 제품
– 실시간 유입 land, conv 데이터 부분

파이프 라인을 설정하지 않고, conf.d에 다수의 설정을 넣을 경우 하나의 파이프 라인에서 동시에 동작하므로 원하는 것과 다른 결과를 낼 수 있습니다. default로 경로인 /etc/logstash/conf.d/*.conf로 로딩 하도록 되어 있는 부분을 파이프 라인에서 설정을 제거하고 각각의 파이프 라인을 추가하여 사용할 수 있습니다.


- cat /etc/logstash/conf.d/star_realtime_conv.conf
# 입력부
input {
# 입력 방식을 file read 방식으로 지정
file {
type => "log4j"
path => "/home/biz/trk007/data/trk_conv_* # trk_conv_로 시작하는 파일을 읽는다.
start_position => "beginning"
sincedb_path => "/home/biz/trk007/sincedb/trk_conv-since.txt" # 처리 내역을 저장할 위치
codec => json # 파일 형식은 JSON 이다.
}
}
# 변경/필터
filter {
# 내용(컨텐츠) TRANSFORM
mutate { # 아래의 컬럼 데이터는 제거한다.
remove_field => [ "vt", "ptm", "is_mobile", "pc_mobile_tp", "dd", "odn", "goal" ]
}
date {
match => [ "stat_date", "ISO8601" ] # 날짜 데이터 이 stat_date format.
target => "stat_date"
}
... (생략) ...
}
# 출력부
output {
#stdout { codec => rubydebug } # 디버깅용, 수동실행시 (콘솔)화면에 출력시 주석 제거
# elasticsearch에 바로 인덱싱(출력) 한다.
elasticsearch {
hosts => [ "http://esm001:9200" ]
index => "realtime_conv-%{[@metadata][index_suffix]}"
# realtime_conv_{오늘자} 인덱스에 인덱싱 한다.
}
}input { } 항목에는 어느 경로에서 데이터 or 로그 파일을 가져올 것인지 확인하며, filter { } 부분에서는 해당 데이터 속성 값을 지정하여 기준이 되는 데이터 정의합니다. 이렇게 명명한 데이터들을 어느 곳으로 보내야 하는지 output { }에 elastic hosts 명시 한 후 Logstash 실행하게 되면 아래와 같이 Elastic에서 저장된 데이터를 확인하실 수 있습니다.
해당 conf.d 설정된 Pipeline에 설정 값들을 따라 업로드 되어진 데이터들을 아래의 Index Manegement에서 확인하실 수 있습니다.

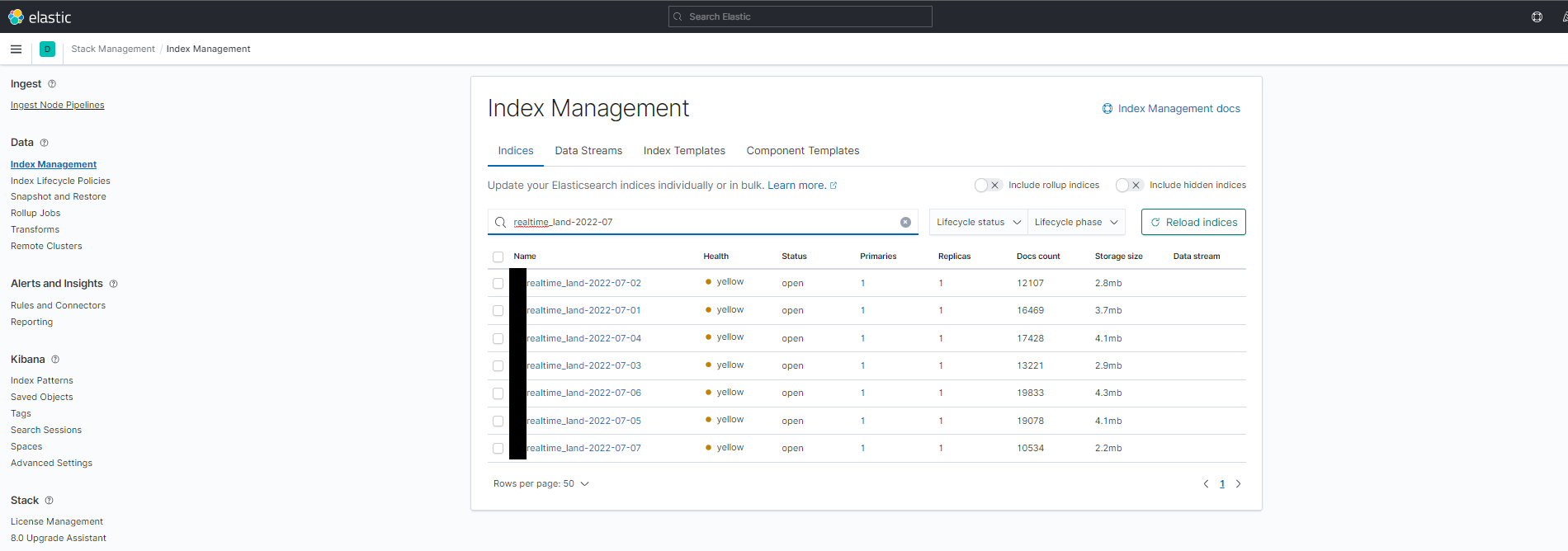
indexing 되어진 실시간 데이터들은 아래와 같이 유입 분석, 트래픽, 성과 추이의 데이터들을 실시간으로 확인 할 수 있습니다.
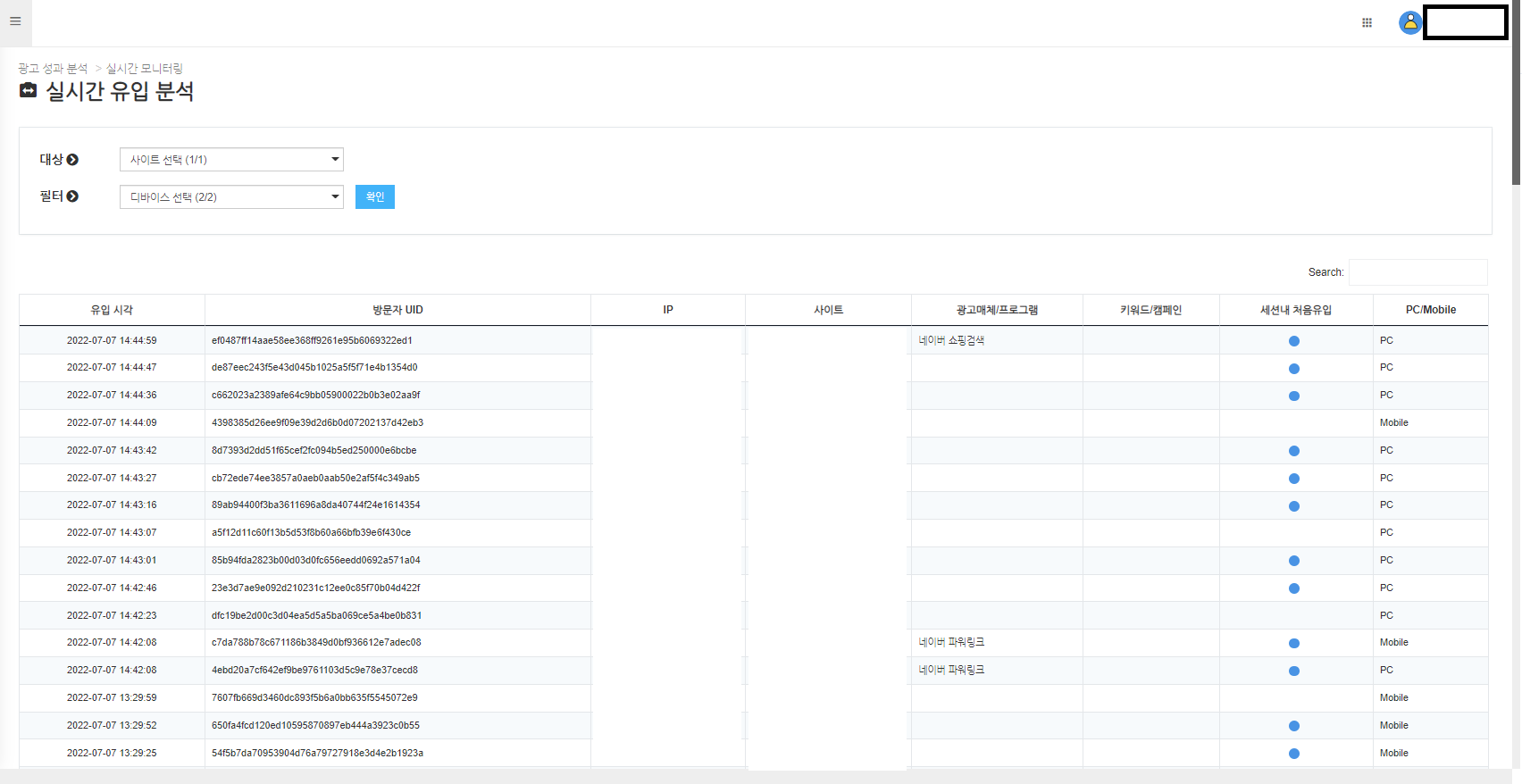
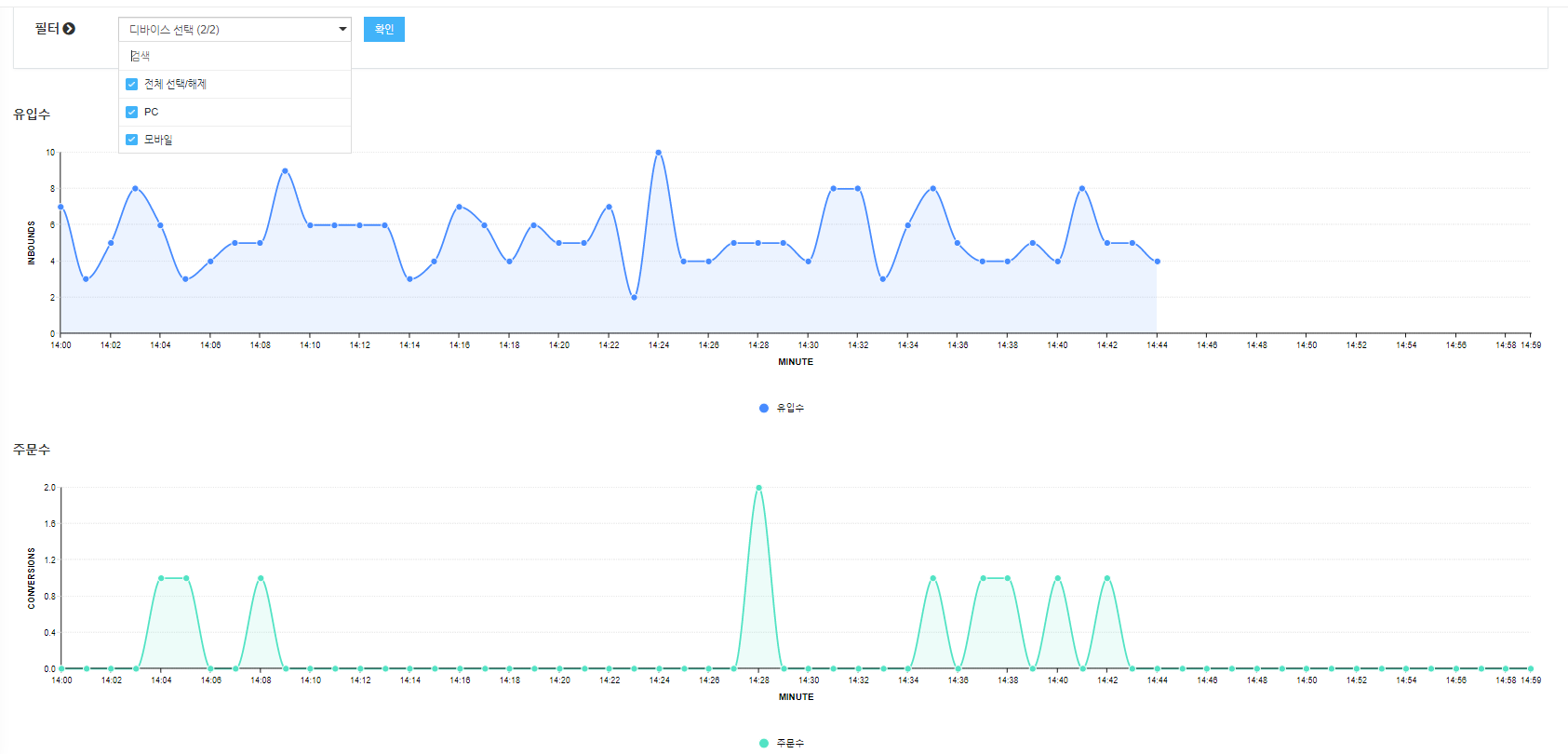
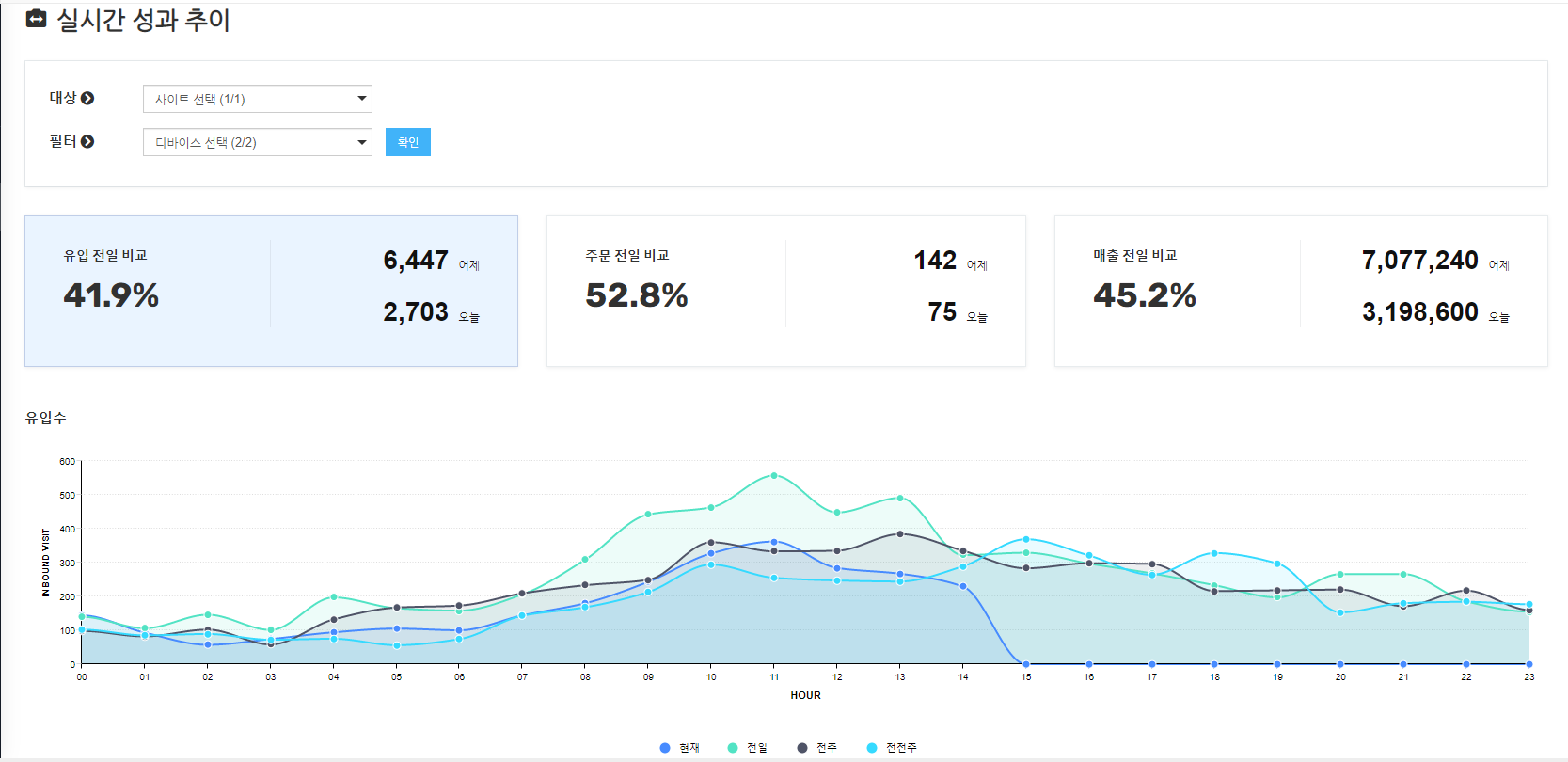
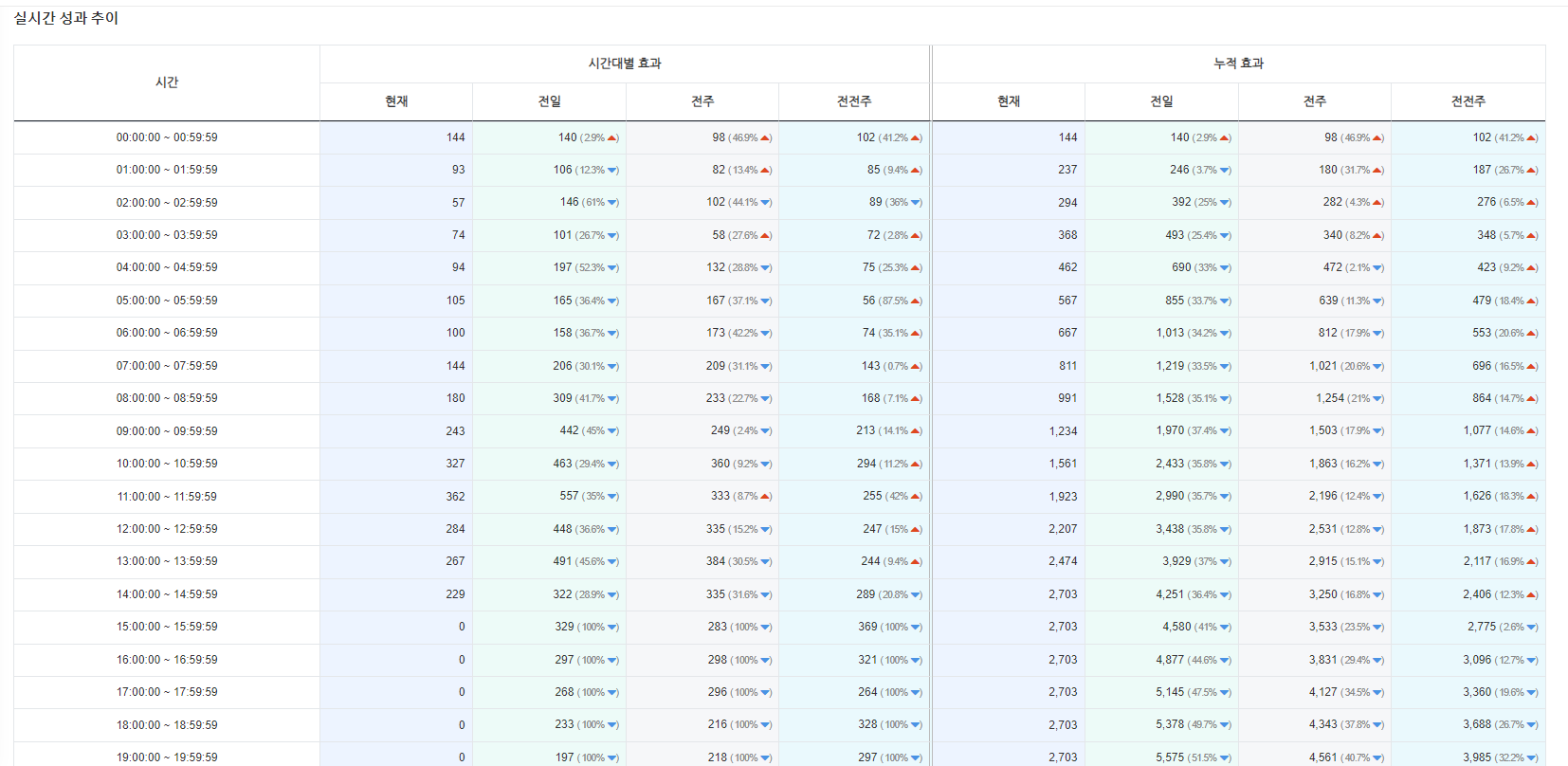
이번 콘텐츠에서는 Logstash 라는 실시간 데이터 처리 엔진을 알아보았는데요,
비즈스프링은 앞서 설명드린 Logstash를 활용하여 자사의 다양한 솔루션에서 실시간 데이터를 제공하고 있습니다. 데이터를 실시간으로 가공하고 전송하여 리포트에서 빠르게 확인할 수 있는 비즈스프링의 솔루션이 필요하거나, Logstash를 활용하여 실시간 데이터 수집에 대해 궁금하시다면 언제든지 비즈스프링과 고민을 나눠주시기 바랍니다.
- 02-6919-5555 / ad@bizspring.co.kr