데이터 분석과 머신러닝의 중요성은 누구나 알지만, 실제로 시작하려면 Python 환경 구성이나 TensorFlow 같은 프레임워크 설치부터 막히는 경우가 많습니다.
BigQuery ML은 2018년 7월 공개된 이후 7년째 운영되고 있으며, 여전히 SQL만으로 머신러닝 모델을 만들 수 있다는 점에서 진입 장벽이 낮습니다. 최근에는 Google Cloud Vertex AI와도 연계되어, 단순 실습용을 넘어 다양한 ML 워크로드를 다룰 수 있는 플랫폼으로 발전했습니다.
이번 포스트에서는 Google이 공개한 샘플 데이터셋을 활용해 모델 생성 → 평가 → 예측까지, 전 과정을 SQL만으로 어떻게 실행할 수 있는지 직접 살펴보겠습니다.
1. 데이터 셋 소개
이번 포스트에 사용할 데이터는 bigquery-public-data.google_analytics_sample 입니다.
Google Merchandise Store의 실제 웹로그 데이터를 기반으로 만들어진 샘플이며, BigQuery에서 누구나 접근할 수 있습니다.
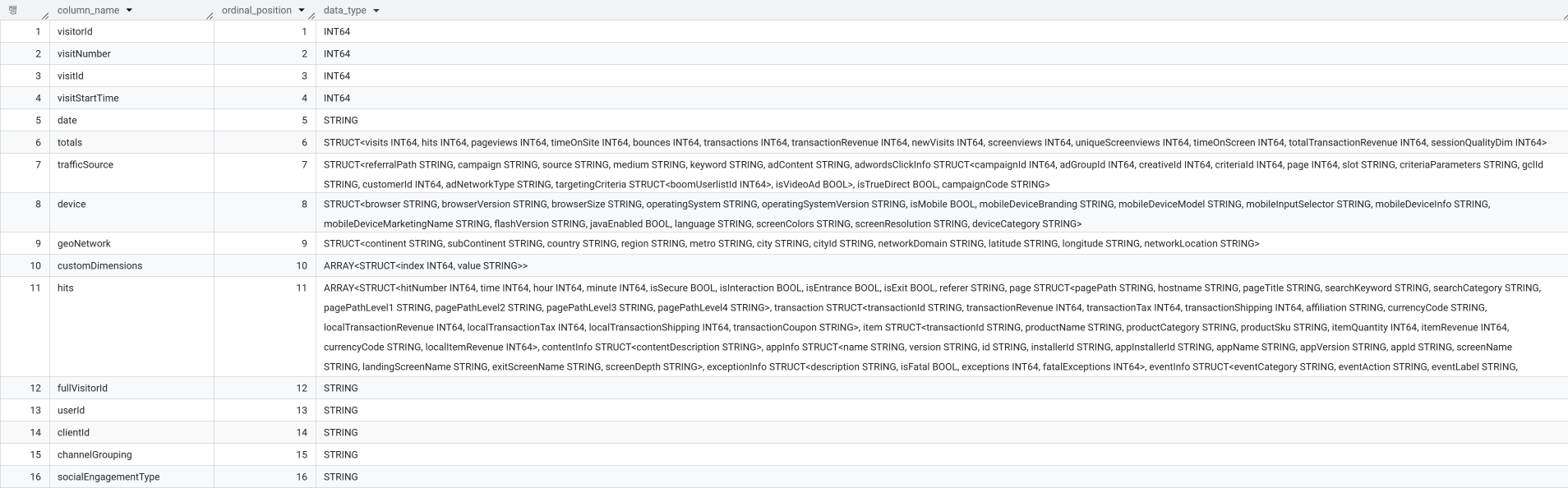
핵심 테이블은 ga_sessions_* 입니다. 날짜 단위로 쪼개져 있으며, 각 세션의 정보가 담겨 있습니다. 스키마는 다소 복잡하지만, 크게 보면 다음과 같은 그룹으로 구성됩니다.
- 트랜잭션 정보: 구매 여부, 구매 건수, 매출 금액
- 디바이스 정보: 브라우저, 운영체제, 모바일 여부 등
- 지역 정보: 국가, 도시, 대륙
- 행동 정보: 페이지뷰, 세션 길이 등
2. 실험 목표
실험 목표는 다음과 같습니다.
“방문자가 세션에서 구매할 확률을 예측할 수 있을까?”
이를 위해 라벨과 피처를 정리합니다.
- 피처(feature): 운영체제, 모바일 여부, 국가, 페이지뷰 수
- 라벨(label): 세션 내 총 전자상거래 수 (거래 수가 NULL이면 열의 값을 0으로 설정. 그렇지 않으면 1로 설정)
-- 2017-07~2017-08 세션 피처 확인용
SELECT
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(totals.pageviews, 0) AS pageviews,
IFNULL(geoNetwork.country, "") AS country,
fullVisitorId
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801';
즉, 세션 단위 데이터를 가지고 “이 세션이 구매로 이어질지”를 분류하는 것이 목표입니다.
3. 모델 학습
BigQuery ML에서는 SQL로 로지스틱 회귀 모델을 만들 수 있습니다.
-- 트랜잭션 유무를 label로 하여 로지스틱 회귀 모델 생성 (2016-08~2017-06 데이터 사용)
CREATE OR REPLACE MODEL `bqml_tutorial.sample_model`
OPTIONS(model_type='logistic_reg') AS
SELECT
IF(totals.transactions IS NULL, 0, 1) AS label,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630';- CREATE MODEL 문은 모델을 만든 다음 쿼리의 SELECT 문으로 검색된 데이터를 사용하여 모델을 학습시킵니다.
- OPTIONS(model_type=’logistic_reg’) 문은 로지스틱 회귀 모델을 만듭니다.
- SELECT 문은 세션 내 총 전자상거래 수, 운영체제, 모바일 여부, 국가, 페이지뷰 수를 열에서 검색합니다.
- FROM 문에서 bigquery-public-data.google_analytics_sample.ga_sessions 샘플을 사용해 모델을 학습시킵니다.
- WHERE 문에서 기간은 2016년 8월 1일 ~ 2017년 6월 30일 구간입니다.
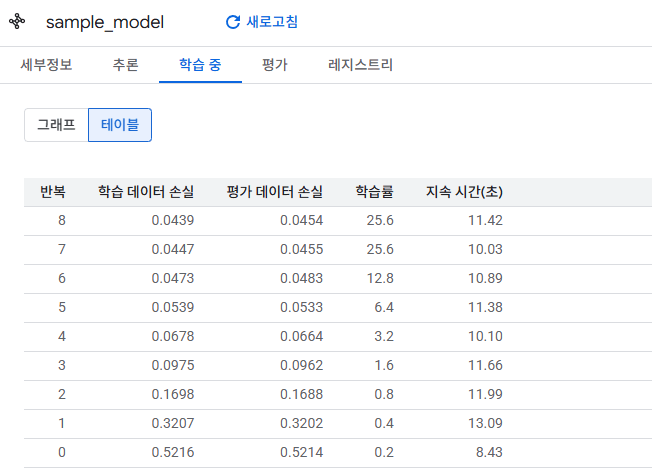
4. 평가
ML.EVALUATE 함수를 사용하여 모델의 성능을 평가할 수 있습니다.
-- 학습된 모델을 2017-07~2017-08 데이터로 평가
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, (
SELECT
IF(totals.transactions IS NULL, 0, 1) AS label,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170801'));- SELECT 문은 모델에서 열을 검색합니다.
- FROM 문은 모델에 ML.EVALUATE 함수를 사용합니다.
- 중첩된 SELECT 문과 FROM 문은 CREATE MODEL 쿼리에 있는 것과 동일합니다.
- WHERE 문에서 학습 데이터 바로 다음 달인 2017년 7월 1일 ~ 2017년 8월 1일 구간을 선택합니다.

BigQuery ML에서는 ML.EVALUATE 결과로 정밀도(precision), 재현율(recall), 정확도(accuracy) 등의 지표를 확인할 수 있습니다. 위 결과는 공개 샘플 데이터로 학습한 단순 예시라 수치 자체에는 큰 의미가 없고, 복잡한 환경 설정 없이 SQL만으로 모델 품질을 검증할 수 있다는 점이 핵심입니다.
5. 예측 결과 확인
이제 학습된 모델을 사용해 테스트 데이터의 구매 예측을 할 수 있습니다.
-- 방문자별 예측 구매 건수 합계 (2017-07~2017-08 테스트 데이터)
SELECT
fullVisitorId,
SUM(predicted_label) as total_predicted_purchases
FROM
ML.PREDICT(MODEL `bqml_tutorial.sample_model`, (
SELECT
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(totals.pageviews, 0) AS pageviews,
IFNULL(geoNetwork.country, "") AS country,
fullVisitorId
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
GROUP BY fullVisitorId
ORDER BY total_predicted_purchases DESC
LIMIT 10;
예를 들어 사용자 9417857471295131045 의 경우, 모델은 약 4번의 구매를 예측했습니다. 실제 데이터에서는 해당 사용자가 5개의 세션에서 총 9건의 구매를 기록했습니다. 완벽하진 않지만 방향성은 어느 정도 맞췄다고 볼 수 있습니다.
또한 BigQuery 쿼리를 통해 트랜잭션 ID, 구매한 상품, 금액까지 실제 기록을 확인할 수 있습니다.
-- 2017-07~2017-08 기간에 실제 구매가 있었던 세션 목록과 금액
SELECT
_TABLE_SUFFIX,
fullVisitorId,
visitId,
DATETIME(TIMESTAMP_SECONDS(visitStartTime), "UTC") AS visit_start_utc,
IFNULL(totals.transactions, 0) AS transactions,
SAFE_DIVIDE(IFNULL(totals.transactionRevenue, 0), 1e6) AS revenue_usd
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
AND fullVisitorId = '9417857471295131045'
AND (totals.transactions > 0 OR totals.transactionRevenue IS NOT NULL)
ORDER BY _TABLE_SUFFIX, visitId;
6. 내부 매커니즘 해부
BigQuery ML은 단순히 예측값만 주는 게 아니라, 모델 내부 계수(weight) 도 확인할 수 있습니다.
-- 모델 가중치(회귀 계수) 목록
SELECT *
FROM ML.WEIGHTS(MODEL `bqml_tutorial.sample_model`)
ORDER BY ABS(weight) DESC;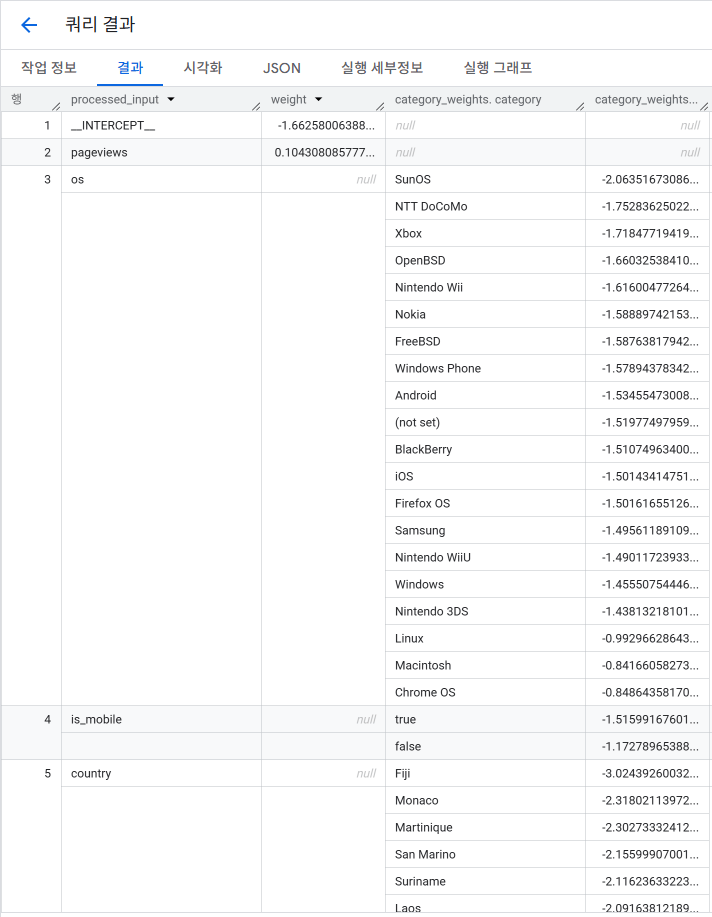
- ML.WEIGHTS 로 로지스틱 회귀 계수를 조회
- INTERCEPT는 모든 feature 값이 0일 때의 log-odds 값
- pageviews는 양수 계수 → 페이지뷰가 많을수록 구매 확률 상승
- os, is_mobile, country 등은 음수 계수 → 구매 확률 하락
직접 수식에 대입해 sigmoid를 계산하면, ML.PREDICT가 내놓은 확률과 일치함을 검증할 수 있습니다.
7. sigmoid 함수로 로지스틱 회귀 예측 확률 검증하기
로지스틱 회귀 모델은 선형 결합 결과 z를 sigmoid 함수에 통과시켜 확률을 계산합니다.
- β0: 인터셉트 (기본값)
- βi: 각 피처(feature)의 가중치
- 𝑥i: 세션에서 관측된 피처값 (𝑥0 = 1)
-- 특정 방문자의 세션 피처값 상세 확인 (2017-07~2017-08)
SELECT
_TABLE_SUFFIX,
fullVisitorId,
visitId,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
AND fullVisitorId = '9417857471295131045'
ORDER BY _TABLE_SUFFIX, visitId
LIMIT 20;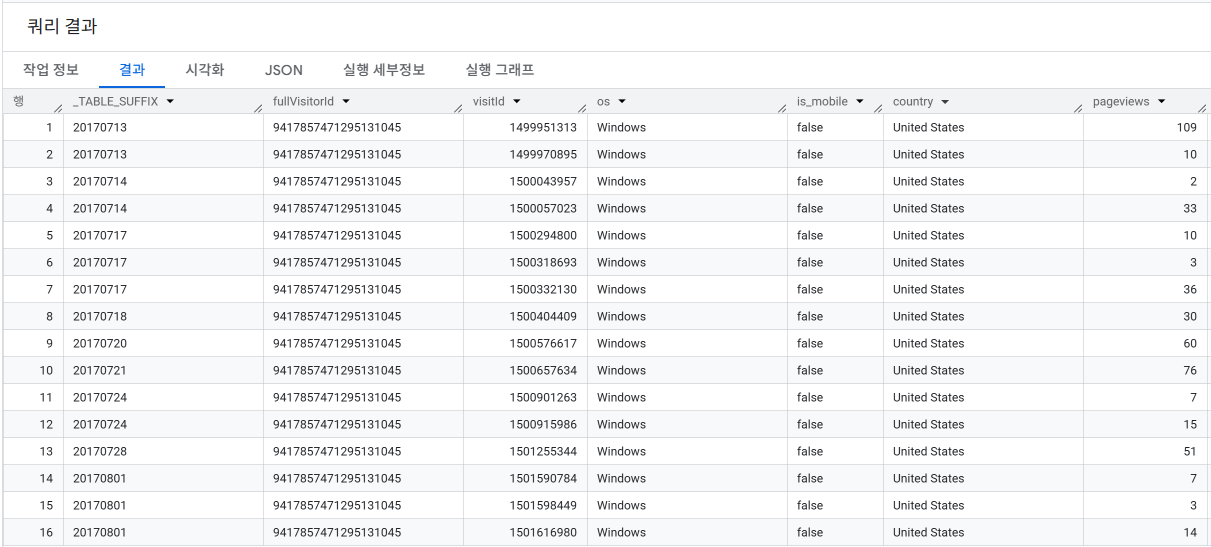
-- 숫자형 피처(pageviews) 및 범주형 피처(os, is_mobile, country)의 가중치 확인
SELECT
w.processed_input,
w.weight AS base_weight,
cw.category AS category,
cw.weight AS category_weight
FROM ML.WEIGHTS(MODEL `bqml_tutorial.sample_model`) AS w
LEFT JOIN UNNEST(w.category_weights) AS cw
WHERE w.processed_input IN ('__INTERCEPT__', 'pageviews')
OR (w.processed_input = 'os' AND cw.category = 'Windows')
OR (w.processed_input = 'is_mobile' AND cw.category = 'false')
OR (w.processed_input = 'country' AND cw.category = 'United States')
ORDER BY w.processed_input;
두 쿼리의 결과를 합치면 실제 로지스틱 회귀 예측 확률을 계산할 수 있습니다.
선형 결합 공식은 다음과 같습니다.
여기서 𝛽 계수는 모델 가중치(ML.WEIGHTS)에서 가져오고, 𝑥 값은 세션 데이터에서 가져옵니다.
예를 들어, 2017-07-13의 한 세션(pageviews = 109)에 대해 계산하면:
sigmoid 적용 공식 :
즉, visitId = 1499951313 인 세션의 구매 확률은 약 99.8%로 추정됩니다.
-- (수동 검증용) 한 세션의 피처값 × 가중치 → z → sigmoid 확률 계산
DECLARE target_fullVisitorId STRING DEFAULT '9417857471295131045';
DECLARE start_suffix STRING DEFAULT '20170701';
DECLARE end_suffix STRING DEFAULT '20170801';
SELECT
p.fullVisitorId, p.visitId,
p.predicted_label,
probs.prob AS prob_predict
FROM ML.PREDICT(
MODEL `bqml_tutorial.sample_model`,
(
SELECT
IFNULL(device.operatingSystem, '') AS os,
device.isMobile AS is_mobile,
IFNULL(totals.pageviews, 0) AS pageviews,
IFNULL(geoNetwork.country, '') AS country,
fullVisitorId, visitId
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE _TABLE_SUFFIX BETWEEN start_suffix AND end_suffix
AND fullVisitorId = target_fullVisitorId
)
) AS p, UNNEST(p.predicted_label_probs) AS probs
WHERE probs.label = 1
ORDER BY visitId;
로지스틱 회귀 모델은 각 세션에 대해 구매(1)일 확률을 출력합니다.
ML.PREDICT 결과에서 predicted_label_probs를 펼치면, 클래스별 확률이 나오며 prob_predict는 그중 구매(1)일 확률을 의미합니다.
예를 들어, 세션 visitId = 1499951313의 경우 prob_predict = 0.9984로 계산되었습니다.
이는 해당 세션이 구매로 이어질 가능성을 99.84%로 추정한 것입니다.
분류 문제에서는 보통 threshold = 0.5를 기본값으로 사용합니다. 즉:
- prob_predict ≥ 0.5 → predicted_label = 1 (구매)
- prob_predict < 0.5 → predicted_label = 0 (비구매)
전체 세션 중 prob_predict ≥ 0.5인 데이터가 4개였고, 이는 모델이 “구매로 분류”한 세션 수와 일치합니다.
즉, sigmoid 계산 → threshold 적용 → 최종 분류라는 로지스틱 회귀의 동작 방식이 BigQuery ML에서도 그대로 적용됨을 확인할 수 있습니다.
8. 결론
- 데이터 준비 → 모델 학습 → 평가 → 예측 → 해석의 전 과정을 SQL만으로 경험할 수 있어 머신러닝 실습이 가능합니다.
- 데이터 이동 없이 BigQuery 안에서 바로 처리 가능하여, 빠른 프로토타입/POC에 유리합니다.
- BigQuery 계정만 있으면 무료 크레딧으로 바로 실습할 수 있습니다.
- 실무적으로는 전환 예측, 이탈 예측, 추천 시스템 등 다양한 문제에 응용할 수 있습니다.
Ref.
SQL을 사용하여 BigQuery ML에서 머신러닝 모델 만들기
Logistic regression – Wikipedia
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.