지난 포스팅에서는 회귀분석을 통해 데이터로부터 인사이트를 얻는 방법에 대해 살펴보았습니다. 오늘은 한 단계 더 나아가 “고객 이탈 예측”이라는 실질적인 비즈니스 문제를 머신러닝 분류 모델로 해결하는 방법을 알아보겠습니다.
🎯 고객 이탈 예측, 왜 중요한가?
고객 이탈은 모든 비즈니스에 치명적인 위험 요소입니다. Harvard Business Review에 따르면 신규 고객을 확보하는 데 드는 비용은 기존 고객을 유지하는 것보다 5~25배 더 높으며, 상위 8%의 충성 고객이 전체 매출의 40%를 차지한다고 합니다.
그렇다면 “어떤 고객이 이탈할 가능이 높은지” 미리 예측할 수 있다면 어떨까요?
데이터 과학과 머신러닝 기반 분류 모델은 이러한 문제에 강력한 해결책을 제공합니다.
💡 머신러닝으로 고객 이탈 예측하기
머신러닝의 분류 모델은 고객의 행동 및 속성 데이터를 분석하여 다양한 인사이트를 도출하는 데 유용합니다. 이를 통해 얻을 수 있는 주요 인사이트는 다음과 같습니다:
- 이탈 가능성 예측
고객별 이탈 확률을 계산하여 고위험 고객을 사전에 식별합니다. - 위험 요인 식별
고객의 행동 및 속성을 분석하여 이탈을 유발하는 주요 요인을 파악합니다. - 맞춤형 대응 전략 수립
고위험 고객에게 적합한 마케팅 전략을 설계하고, 사전 대응으로 고객 이탈을 줄입니다.
실제 고객 이탈 예측 모델을 구현하기 위해서는 체계적인 프로세스가 필요합니다. 고객 이탈 예측의 전체 흐름은 아래와 같습니다.
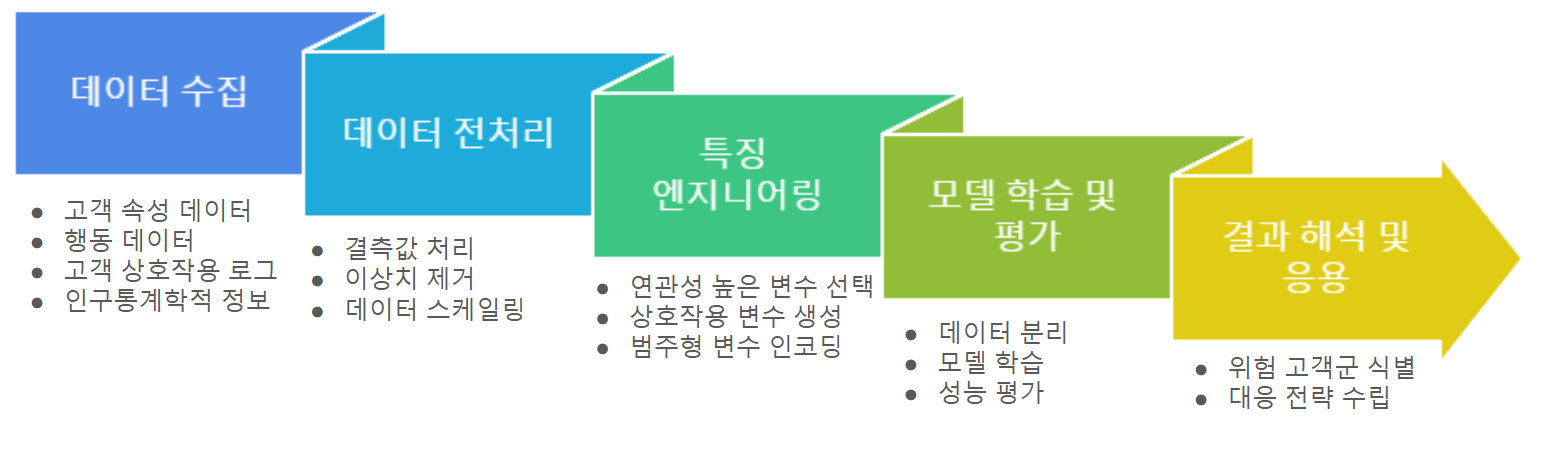
💻 Python으로 구현하는 간단한 이탈 예측 모델
이제 Python을 사용하여 간단한 고객 이탈 예측 모델을 구현해보겠습니다. 아래 코드는 샘플 데이터를 생성하고, 머신러닝 모델을 학습하여 이탈 가능성을 예측하는 과정을 보여줍니다.
1. 데이터 생성 및 파생 변수 추가
먼저 고객 데이터를 생성하고, 예측에 필요한 파생 변수를 추가합니다.
import pandas as pd
import numpy as np
# 샘플 데이터 생성 및 파생 변수 추가
np.random.seed(42)
def generate_customer_data(n_samples=1000):
data = {
'사용기간': np.random.randint(1, 60, n_samples), # 고객 사용 기간 (개월)
'구매빈도': np.random.randint(1, 20, n_samples), # 고객의 구매 빈도
'평균구매금액': np.random.normal(50000, 20000, n_samples), # 고객의 평균 구매 금액
'문의횟수': np.random.randint(0, 10, n_samples), # 고객의 서비스 문의 횟수
}
df = pd.DataFrame(data)
# 파생 변수 생성
df['월평균구매금액'] = df['평균구매금액'] / df['사용기간']
df['사용기간_구매빈도'] = df['사용기간'] / (df['구매빈도'] + 1) # 0 방지
# 이탈 여부 생성: 예시 조건에 맞는 고객을 이탈한 고객으로 지정
df['이탈여부'] = (
(df['사용기간'] < 12) &
(df['구매빈도'] < 5) &
(df['평균구매금액'] < 30000) |
(df['문의횟수'] > 7)
).astype(int)
return df
df = generate_customer_data()2. 데이터 전처리
데이터를 학습용과 테스트용으로 나누고, 스케일링을 적용합니다.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 분할 및 스케일링
X = df[['사용기간', '구매빈도', '평균구매금액', '문의횟수', '월평균구매금액', '사용기간_구매빈도']]
y = df['이탈여부']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)3. 특징 중요도 분석
랜덤포레스트를 사용하여 각 특징의 중요도를 분석하고, 이를 시각화합니다.
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns
# 랜덤포레스트로 특징 중요도 추출
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train_scaled, y_train)
# 중요도 시각화
importances = rf.feature_importances_
features = X.columns
importance_df = pd.DataFrame({'특징': features, '중요도': importances}).sort_values(by='중요도', ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='중요도', y='특징', data=importance_df, palette='viridis')
plt.title('특징 중요도 분석')
plt.show()
4. 모델 학습 및 성능 평가
다양한 모델(로지스틱 회귀, 의사결정나무, 랜덤포레스트)을 학습시키고 성능을 평가합니다.
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
# 모델 학습 및 평가 함수
def evaluate_model(model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"{type(model).__name__} 성능 평가:")
print(classification_report(y_test, y_pred))
# 혼동행렬 시각화
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{type(model).__name__} 혼동행렬')
plt.ylabel('실제 값')
plt.xlabel('예측 값')
plt.tight_layout()
plt.show()
# 모델 리스트
models = [
LogisticRegression(),
DecisionTreeClassifier(random_state=42),
RandomForestClassifier(random_state=42)
]
for model in models:
evaluate_model(model, X_train_scaled, X_test_scaled, y_train, y_test)
📈 모델별 특징 및 활용 사례
각 머신러닝 모델의 특징과 장단점을 아래와 같이 비교할 수 있습니다:
| 모델 | 장점 | 한계 | 적합한 경우 |
| Logistic Regression | 간단하고 빠른 계산, 해석 용이 | 비선형 관계에 한계 | 선형적 데이터, 초기 분석 단계 |
| Decision Tree | 가독성 높은 분류 기준, 비선형 처리 가능 | 과적합 위험 | 직관적 규칙이 필요한 경우 |
| Random Forest | 높은 예측 성능, 과적합 방지 | 계산 복잡도 높음 | 복잡한 데이터, 높은 정확도 요구 |
성능 평가 결과
| 모델 | 정확도(Accuracy) | 정밀도(Precision) | 재현율(Recall) | F1 점수 (F1 Score) |
|---|---|---|---|---|
| Logistic Regression | 0.78 | 0.76 | 0.80 | 0.78 |
| Decision Tree | 0.82 | 0.81 | 0.83 | 0.82 |
| Random Forest | 0.89 | 0.88 | 0.91 | 0.89 |
위 결과에서 Random Forest 모델이 가장 높은 정확도와 안정적인 성능을 보여주었습니다.
🚀 마치며
고객 이탈 예측은 단순히 데이터를 분석하는 것 이상의 의미를 가집니다. 이를 통해 고객의 행동을 예측하고, 적시에 대응함으로써 고객 충성도를 높이고, 수익성을 향상시킬 수 있습니다.
비즈스프링은 머신러닝 기반의 데이터 분석 기술을 통해 고객의 숨은 신호를 읽어내고, 기업의 지속 가능한 성장을 지원합니다. 지금 여러분의 데이터를 분석하여 숨겨진 신호를 발견하고, 성공적인 고객 유지 전략을 설계해 보세요!