☑️이 글을 읽고 나면 알게 되는 것들
- 카프카가 무엇인지 한마디로 정의할 수 있다.
- 카프카의 구조를 3줄로 정리할 수 있다.
- zookeeper 과 kafka 모드를 구분할 수 있다.
- kafka를 설치하고 간단하게 클러스터 환경을 구성하여 Producer 및 Consumer 테스트를 할 수 있다.
카프카란 무엇인가요?
” 대량의 데이터를 안정적이고 실시간으로 처리할 수 있는 시스템”

마치 거대한 중앙 우체국와 같이 모든 이벤트/데이터 흐름을 중앙에서 관리할 수 있어, 한 곳에서 데이터를 관리하며 데이터를 이용한 다양한 분석을 가능하게 합니다.
기존에 RBDMS 으로는 관리할 수 없는 정적이고, 복잡성과 다양성을 띈 데이터를 처리할 수 있는 ‘스트리밍 데이터’ 를 관리 할 수 있습니다. 이를 바탕으로 카프카는 RDBMS의 트랜잭션 로그 마이너 기술 영향을 받아 만들어졌다고 합니다.(데이터가 생성, 변경될 때마다 로그를 기록)
위의 나열한 카프카(Kafka)의 특성 때문에, 카프카(Kafka)는 시스템 또는 애플리케이션 간의 실시간 데이터 파이프라인을 만들때 사용하며, 대용량 실시간 로그 처리에 특화되어 있어, 데이터를 유실 없이 안전하게 전달하는 것이 주 목적인 메세지 시스템에 활용되고 있습니다. 또한, 이벤트 주도 마이크로 서비스 환경에서 각 서비스 이벤트를 연동할 때도 사용되고 있습니다.
기존에는 ActiveMQ, RabbitMQ등 전통적인 메세징 시스템으로 전송한 데이터를 메모리를 사용하여 유지하였다면, 카프카의 경우 프로듀서가 생성된 메세지를 파일 시스템에 저장하여 메세지 보존 기간 내에는 언제든지 읽을 수 있고, 풀(Pull) 방식의 당겨오는 등의 특징이 있다고 볼 수 있습니다.사실 이러한 설명을 이해 하기 위해서는 카프카의 기능을 알아야합니다. 아래 간단하게 카프카의 구조를 알아보도록 하겠습니다.
카프카의 구조
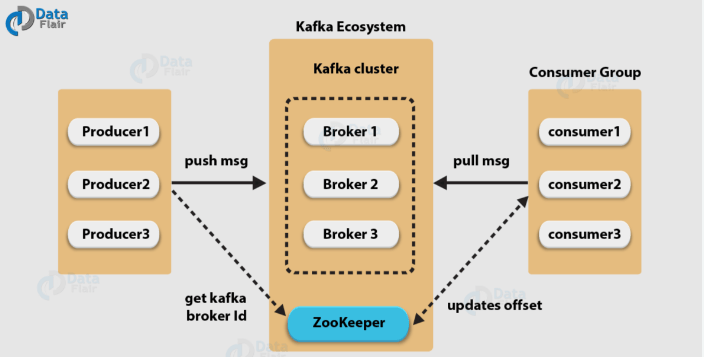
카프카의 구조는 ①프로듀서(Producer), ②주키퍼 클러스터(Zookeeper Cluster), ③카프카 클러스터(Kafka Cluster), ④컨슈머(Consumer(으로 나눌 수 있으며, 카프카 클러스터의 경우 메세지(이벤트)를 저장하는 데 여러 개의 브로커로 구성되어 있습니다. 브로커는 메세지 저장 하는 역할을 하며, 주키퍼 클러스터의 경우는 카프카 클러스터 관리를 합니다. 프로듀서는 메세지(이벤트)를 카프카에 넣으며, 컨슈머는 메세지(이벤트)를 카프카에서 읽습니다.
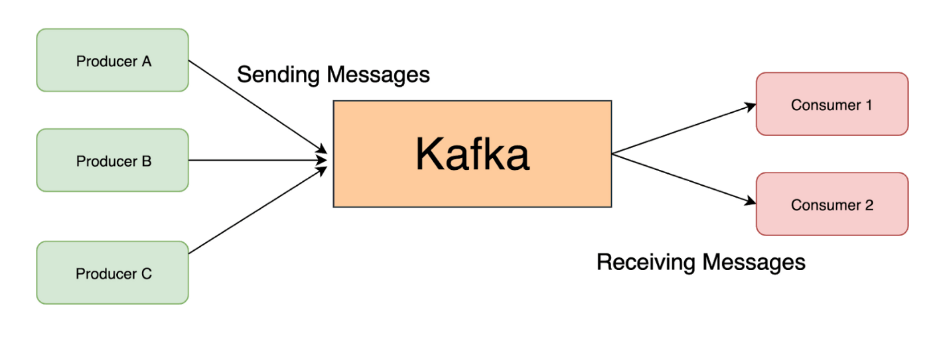
기본적으로 토픽은 메세지를 구분하는 단위이며, 파일 시스템 폴더와 유사하고, 프로듀서와 컨슈머는 토픽을 기준으로 메세지를 주고 받는 역할을 하게 됩니다.
파티션(Partition)과 오프셋(Offset), 메세지 순서 (Message Sequences)
파티션은 추가가 가능한 파일이며, 각 메시지 저장 위치를 오프셋이라고 합니다. 프로듀서(Producer)가 넣은(Push) 메세지는 파티션 맨 뒤에 추가 되며, 컨슈머(Consumer)는 오프셋 기준으로 메세지를 순서대로 읽게되며, 메세지는 삭제되지 않습니다. ( 단, 설정에 따라 일정 시간이 지난 뒤 삭제)
프로듀서는 라운드 로빈(Round-Robin) 또는 키(Key)로 파티션(Partition) 이 선택되고, 같은 키를 갖는 메세지는 같은 파티션에 저장됩니다. 단 같은 키는 순서 유지가 됩니다.
컨슈머(Consumer)는 컨슈머 그룹 (Group)에 속하고, 한 개 파티션(Partition) 은 컨슈머 그룹의 한 개 컨슈머만 연결 가능하며, 한 컨슈머 그룹 기준으로 파티션의 메시지를 순서대로 처리하게 되어있습니다.
카프카의 성능
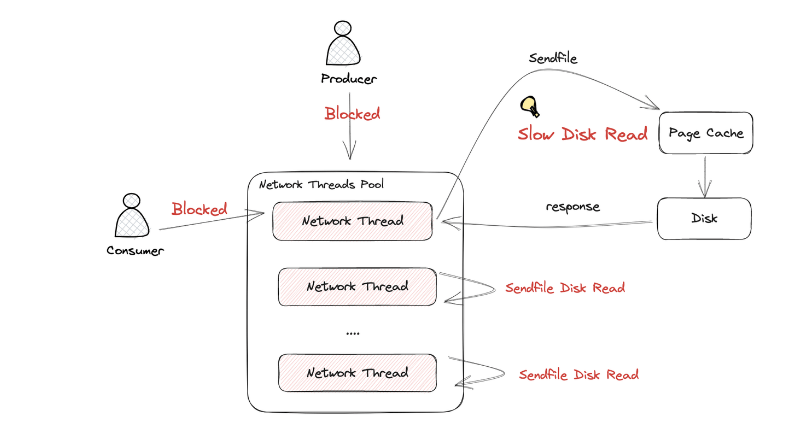
이에 대한 기능을 올바르게 작동하려면 성능 부분에서 어떻게 수행되는지 알아볼 필요가 있습니다.
파티션 파일은 기본적으로 OS 페이지 캐시를 사용하게되는데, 파티션에 대한 파일 IO를 메모리에서 처리하게 되어 있습니다. 서버에서만 페이지 캐시(Page-Cache) 를 카프카만 사용해야 성능에 유리하게 됩니다.
*Zero Copy의 경우 디스크 버퍼에서 네트워크 버퍼로 직접 데이터를 복사하게 되는데, 컨슈머 추적을 위해 브로커가 하는 일이 비교적 단순합니다. 메세지 필터, 메시지 재 전송과 같은 일은 브로커가 하지 않고, 프로듀서와 컨슈머가 직접하며, 이 때문에 브로커는 컨슈머와 파티션 간 매핑 관리를 하게 됩니다.
또한 카프카는 배치 작업을 통해 묶어서 보내거나, 묶어서 받는 역할을 하는데요. 프로듀서는 일정 크기만큼 메세지를 모아서 전송가능하고, 컨슈머는 최소 크기만큼 메세지를 모아서 조회가 가능합니다. 이 때문에 낱개 처리보다 처리량이 증가하게 되어, 이러한 특성때문에 카프카는 처리량(Throughout) 증대(확장)이 쉽다고 말할 수 있습니다. 1개의 장비가 용량 한계가 다다를때 브로커와 파티션을 추가하고, 컨슈머를 추가하게되면 파티션이 추가되게 됩니다.
* 여기에서 Zero-Copy 란, 데이터를 검사하거나 수정하지 않고 바이트 형식으로 전송하며, 클러스터 수준에서는 데이터 검증이 하지 않으며, 불필요한 복사 없이 데이터가 디스크에서 네트워크로 직접 이동하는 걸 말합니다.
리플리카는 파티션의 복제본 이라고 말할 수 있습니다. 복제 수 만큼 파티션의 복제본이 각 브로커가 생기게 됩니다.
또한 리더와 팔로워로 구성되어, 프로듀서와 컨슈머는 리더를 통해서만 메시지를 처리하게 되며, 팔로워는 리더로부터 복제하게 됩니다. 이는 장애가 발생할 시, 리더가 속한 브로커 장애 시, 다른 팔로워가 리더가 됩니다.
Zookeeper vs Kraft 모드
기존 Apache Kafka는 ZooKeeper을 통해 브로커,토픽, 파티션 정보 저장을 처리하였는데요. ZooKeeper가 가진 한계를 해결하고자 2019년에 제안된 KRaft모드를 도입하여 ZooKeeper 의존을 제거하였습니다.
ZooKeeper가 카프카에서 맡았던 역할 중에 메타 데이터 처리 병목이라던지, 배포, 모니터링, 백업해야하는 부담이 지속적으로 확인되었고, 이를 해결하기 위해 Kraft 모드를 사용하게 되었습니다.
| 배포 복잡도 | 두 스택 관리 | 단일 스택 배포, 업그레이드 |
| 메타데이터 처리량 | znode워치 병목 | Raft 로그 스트림, 파티션 수 한계 |
| 리더 선출 시간 | seconds | mile seconds |
| 노드 수 | 브로커 N + Zookeeper 3 | 브로커 N + 컨트롤러3 (공유가능) => 인프라 의존도 down |
| 동적 설정 | Zookeeper 트리에 작성 | 컨트롤러 API로 로그 커밋 |
Srimizi Operator 사용하여 간단히 카프카 이용해보기
Strimizi Operator는 쿠버네티스 환경에서 설치와 운영을 단순화 하였는데, 쿠버네티스 CRD를 이용하여 주키퍼, 카프카 클러스터를 설치할 수 있으며 토픽 및 CRD 를 관리할 수 있습니다. 이를 사용해서 간단히 카프카 클러스터를 사용해보겠습니다.
아래 링크로 접속하면, 다양한 유형의 스토리지를 활용 KRaft 의 예시들을 확인할 수 있습니다.
– https://github.com/strimzi/strimzi-kafka-operator/tree/main/examples
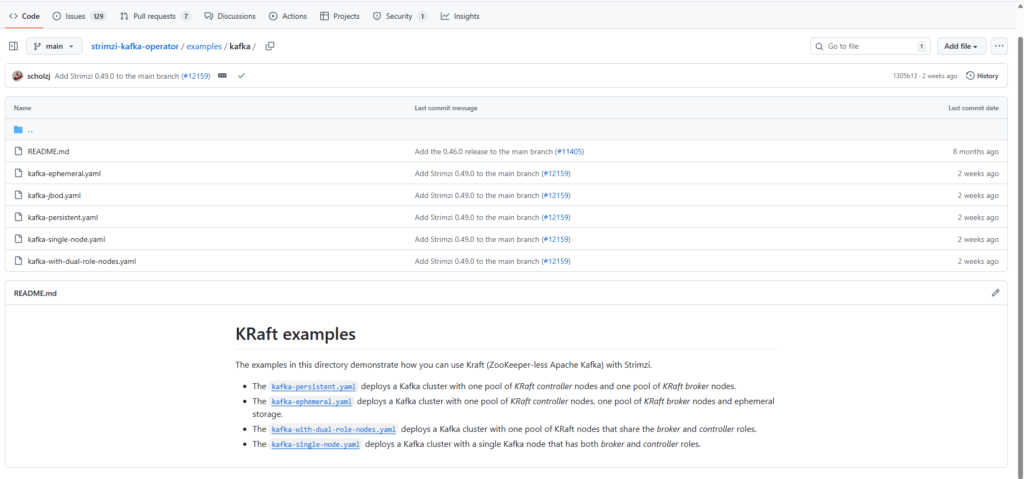
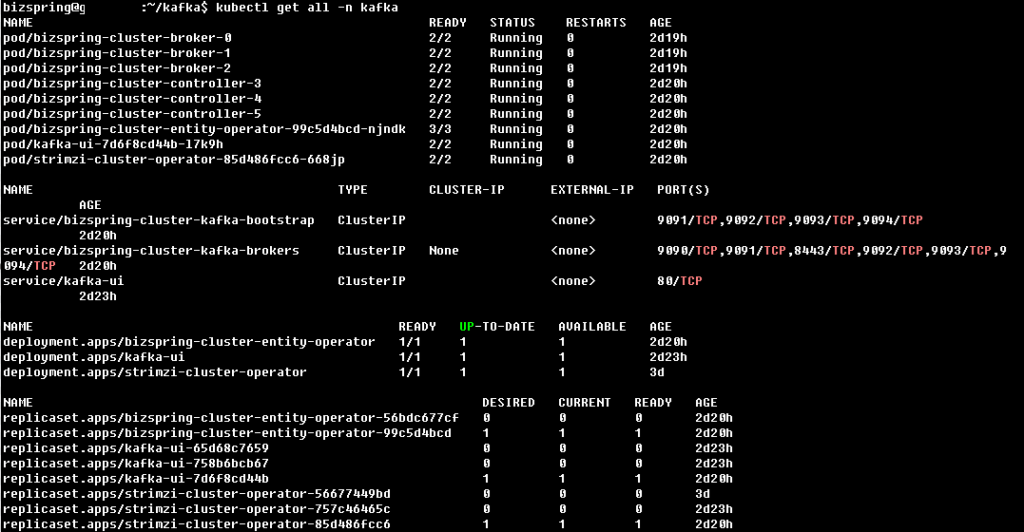
아래는 kafka-ephemeral.yaml 를 사용하여 임시저장소 역할을 할 수 있도록 스토리지 구성한 예시입니다. Kafka 브로커나 Zookeeper에 저장되는 모든 데이터 ( Kafka 메시지 로그, Zookeerper/Kraft 메타 데이터 등)는 해당 Pod이 실행되는 동안에만 유지되는 설정으로 Kafka Cluster 를 배포한 모습입니다.
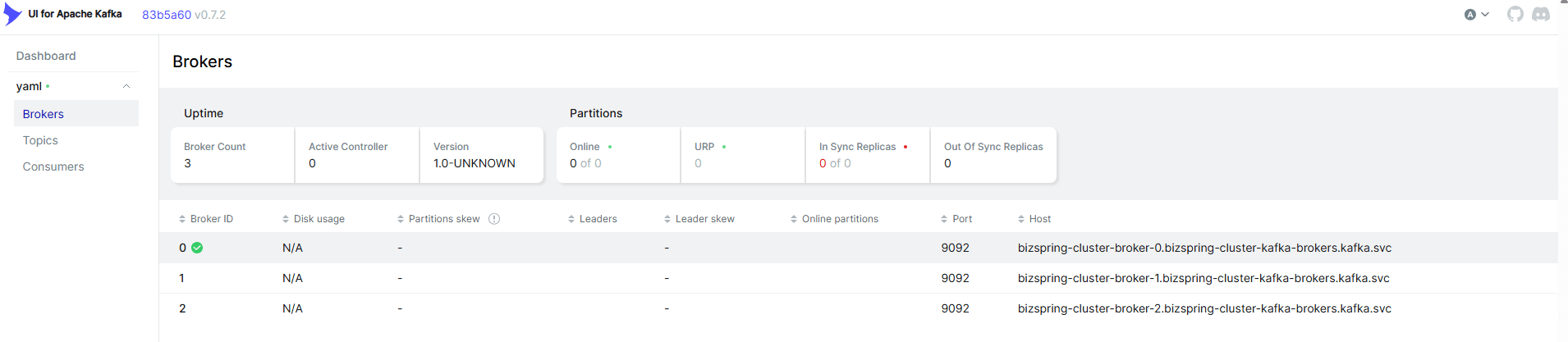
Kafka-UI의 경우는 Helm차트를 사용하여 배포 처리하여 확인할 수 있도록 구성하였습니다.
kafka namespace 생성 후 https://strimzi.io/install/latest?namespace=kafka 을 사용해 apply 합니다. 어떤 환경 구성을 하는지에 따라 다를 것이고, UI의 경우는 Helm chart 를 사용해서 install 을 진행하였습니다.
kubectl create namespace kafka
kubectl apply -f ‘https://strimzi.io/install/latest?namespace=kafka’ -n kafka
helm repo add kafka-ui https://provectus.github.io/kafka-ui-charts
helm install kafka-ui kafka-ui/kafka-ui -f kafka-ui-values.yaml -n kafka
정리
이 글을 다 읽고나니 카프카가 무엇인지 조금은 알수 있을 것 같지 않나요. 카프카는 기본적으로 Publish-SubScribe 모델을 구현한 분산 메세징 서비스 시스템입니다. 이제는 앞전의 정의에 대해서 이해할 수 있고, 전체적으로 카프카의 구조를 알 수 있게 되었습니다. 이러한 카프카는 기존 사용했던 구조 대비 대규모 데이터보다는 간단한 이벤트를 전송하는데 주로 사용되었기 때문에 성능 면에서는 약하였으나, 이러한 단점을 보완한 것이 카프카 메세징 서비스 입니다. 기존 End-to End 연결 방식을 가지고 있는 중앙 전송 영역의 부재, 증설 문제와, 연결시스템 마다 제 각기 다른 방식으로 구현될 수 있는 문제점을 해결하기 위해 모든 시스템으로 데이터를 전송하며 실시간 처리 가능하며, 급속도로 성장하는 서비스를 위해 확장이 용이한 카프카를 다음 시간에는 기능별 주제 별로 알아보는 시간을 가지도록 하겠습니다. 감사합니다.
Referneces
- kafka 조금 아는 척하기 1,2,3 (개발자용)https://www.youtube.com/watch?v=0Ssx7jJJADI&t=140s
- https://aws.amazon.com/ko/what-is/apache-kafka/
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.