이전 글 보기: 콜드 스타트, 생성형 AI가 답이 될 수 있을까? (1)
생성형 AI, 게임 체인저가 되다
최근 등장한 생성형 AI, 특히 대규모 언어 모델(LLM)은 콜드 스타트 문제에 새로운 가능성을 제시합니다. LLM은 방대한 텍스트 데이터에서 학습한 지식과 맥락 이해 능력을 바탕으로, 기존 추천 시스템의 한계를 극복할 수 있습니다.
LLM이 콜드 스타트 문제에 적합한 이유
- 적은 데이터로도 초기 추천 가능: 사전 학습된 방대한 지식을 활용해 데이터 부족 문제 완화
- 비정형 데이터 처리 능력: 구조화되지 않은 텍스트나 다양한 형태의 입력에서 의미 추출 가능
- 다양한 데이터 통합: 여러 데이터 소스를 조합해 더 풍부하고 개인화된 추천 제공
- 창의적 연결과 유연한 추론: 기존 데이터에 없는 새로운 관계나 패턴 도출
주요 활용 방식
1. 적은 데이터로 사용자 프로필 생성하기
LLM은 간단한 사용자 정보만으로도 풍부한 선호도 프로필을 생성할 수 있습니다.
# 기본 정보로부터 확장된 사용자 프로필 생성
def generate_enriched_user_profile(basic_user_info):
# 기본 사용자 정보를 기반으로 프롬프트 구성
prompt = f"""
다음 사용자 정보를 기반으로 선호도와 관심사가 포함된 상세한 사용자 프로필을 작성하세요.
- 나이: {basic_user_info['age']}
- 지역: {basic_user_info['location']}
- 직업: {basic_user_info['occupation']}
- 기본 관심사: {', '.join(basic_user_info['interests'])}
다음 범주에 대한 예상 선호도를 포함하세요:
1. 제품 카테고리
2. 콘텐츠 유형
3. 선호 브랜드
4. 가격 민감도
5. 의사결정 요소
그리고 이 정보를 바탕으로 아래 항목을 JSON 형식으로 제공해주세요:
1. 사용자가 관심을 가질 가능성이 높은 주제 5가지
2. 사용자가 선호할 가능성이 높은 제품 카테고리 3가지
3. 사용자의 구매 의사결정에 중요한 요소 3가지
출력 예시 (JSON 형식):
{{
"interested_topics": ["주제1", "주제2", "주제3", "주제4", "주제5"],
"preferred_product_categories": ["카테고리1", "카테고리2", "카테고리3"],
"decision_factors": ["요소1", "요소2", "요소3"]
}}
"""
# LLM API 호출
response = llm_client.completion(prompt=prompt)
# 응답 반환
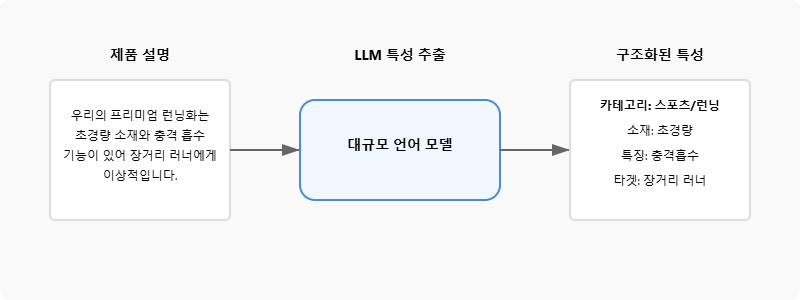
return response2. 제품 설명에서 의미 있는 특성 추출하기
LLM은 제품 설명, 리뷰, 마케팅 텍스트 등에서 중요한 특성과 속성을 추출하고, 이를 구조화된 데이터로 변환할 수 있습니다.
3. 자연어 기반 맞춤형 추천 생성
LLM은 사용자 요청을 이해하고 설득력 있는 맞춤형 추천과 그 이유를 제시할 수 있습니다.
def generate_personalized_recommendations(user_profile, available_items, user_query=None, n=5):
# 사용자 프로필 및 쿼리 기반 프롬프트 구성
prompt = f"""
다음은 사용자 프로필 및 현재 쿼리입니다:
{json.dumps(user_profile, indent=2)}
현재 쿼리:
{user_query if user_query else "일반 추천"}
추천 가능한 아이템 목록:
{json.dumps(available_items, indent=2)}
위 정보를 기반으로 사용자에게 가장 적합할 것 같은 상위 {n}개 아이템을 추천해 주세요.
각 추천 아이템에 대해 다음 정보를 포함해 주세요:
1. 제품명
2. 주요 판매 포인트
3. 사용자의 선호도 및 현재 쿼리와의 적합성 이유
결과는 JSON 형식으로 반환해 주세요.
**JSON 출력 예시:**
{{
"recommendations": [
{{
"product_name": "제품명1",
"key_selling_points": ["포인트1", "포인트2"],
"personalized_reason": "이 사용자가 해당 제품을 선호할 이유"
}},
{{
"product_name": "제품명2",
"key_selling_points": ["포인트1", "포인트2"],
"personalized_reason": "사용자의 관심사 및 쿼리와의 관련성 설명"
}}
// 추천 아이템 {n}개 모두 포함
]
}}
"""
# LLM API 호출
response = llm_client.completion(prompt=prompt)
# 응답 반환
return response하이브리드 접근법: 최선의 전략
AI와 기존 방식의 조화로운 통합
콜드 스타트 문제를 효과적으로 해결하기 위해서는 생성형 AI와 기존 추천 기법을 조화롭게 통합하는 것이 중요합니다. 각 단계별로 데이터 가용성에 맞춘 접근 방식을 적용하면 더 나은 추천 성능을 달성할 수 있습니다.
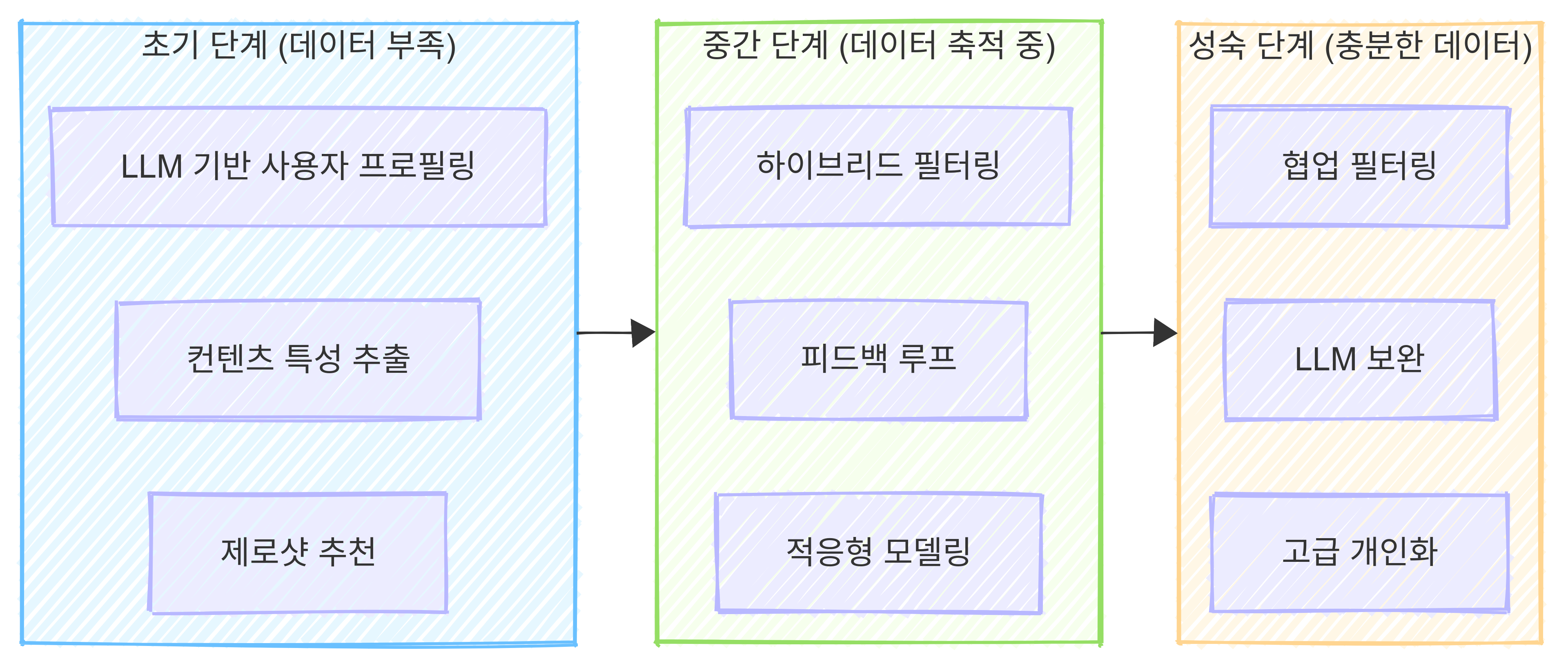
1. 초기 단계 (데이터 부족)
🔍 LLM의 역할: 데이터가 거의 없는 시기에는 생성형 AI의 추론 및 사전 학습 지식을 적극 활용합니다.
- 사용자 프로필 생성: 적은 사용자 정보로도 풍부한 선호도 프로필 작성
- 컨텐츠 특성 추출: 제품 설명이나 리뷰에서 핵심 특성 및 속성 추출
- 제로샷 추천: 추가 학습 없이 자연어 입력만으로 맥락 기반 추천 제공
- 메타데이터 강화 : LLM을 사용해 기존 데이터에 새로운 속성 추가 및 보완
2. 중기 단계 (데이터 축적 중)
🔄 AI와 데이터의 시너지: 사용자 행동 데이터가 쌓이기 시작하면 LLM과 기존 기법을 통합합니다.
- LLM 기반 프로필 + 실제 행동 데이터 결합: 개인화 정확도 개선
- 하이브리드 필터링: 협업 필터링과 컨텐츠 기반 필터링의 균형 유지
- 피드백 루프: 사용자 반응을 학습하여 지속적인 추천 모델 개선
- 적응형 가중치 조정: 데이터 증가에 따른 모델 영향력 조정
3. 성숙기 (충분한 데이터)
📊 데이터 중심 접근: 데이터가 충분할 때는 협업 필터링을 중심으로 고도화합니다.
- 협업 필터링 중심: 풍부한 행동 데이터 기반으로 개인화 강화
- LLM 보완: 설명 가능한 추천 제공 및신규 아이템 콜드 스타트 완화
- 고급 개인화: 멀티모달 데이터와 상황 인식을 통해 정교한 추천 구현
비용 효율성과 구현 복잡도
| 접근법 | 초기 개발 비용 | 운영 비용 | 정확도 | 구현 복잡도 |
| 인기 기반 | 낮음 | 매우 낮음 | 낮음 | 낮음 |
| 컨텐츠 기반 | 중간 | 낮음 | 중간 | 중간 |
| 협업 필터링 | 높음 | 중간 | 높음 | 높음 |
| LLM 기반 | 중간 | 높음 | 중간-높음 | 중간 |
| 하이브리드 | 높음 | 중간-높음 | 매우 높음 | 매우 높음 |
마무리
생성형 AI는 콜드 스타트 문제에 대한 단순한 해결책을 넘어, 추천 시스템의 패러다임을 변화시키는 ‘게임 체인저’로 자리매김하고 있습니다. 데이터가 부족한 초기에는 효과적인 추천을 제공하고, 사용자의 선호를 능동적으로 학습하여 데이터가 충분해진 후에는 맥락 이해와 설명력을 바탕으로 사용자 경험을 더욱 정교하게 만듭니다.
그러나 생성형 AI의 진정한 가치는 기존 기술과의 조화로운 통합에서 찾을 수 있습니다. 현실적인 비용, 데이터 품질, 시스템 통합 등을 고려하며 기존 방법과의 균형을 이루는 하이브리드 접근이 최적의 전략이 될 것 입니다.
다음 편에서는 추천 시스템의 성능을 측정하고 지속적으로 개선하기 위한 방법, 윤리적 고려사항, 그리고 생성형 AI가 만들어갈 미래에 대해 살펴보겠습니다.
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.