LLM 모델의 응답 정확도를 향상시키기 위해서는 RAG 기술의 적용이 필수적입니다. RAG에 필요한 데이터를 저장하는 벡터 데이터베이스에는 Faiss, Chroma, Elasticserach 등이 있습니다.
이번 글에서는 Elasticsearch 기반의 벡터 데이터베이스를 구성하고 간단한 예시를 살펴 보겠습니다.
Requirements
- Python
- Elasticserach(docker)
- ollama
Elasticsearch
version: "3.8"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.17.1
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms1g -Xmx1g
- ELASTIC_PASSWORD=changeme
volumes:
- es_data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
networks:
- elastic- Elasticserach를 벡터 데이터베이스로 사용하기 위해서는 8버전 이상의 Elasticserach가 필요합니다. 여기서는 8.17.1버전의 이미지를 사용했습니다.
- 8.x 버전 이후의 Elasticserach는 Authentication 설정이 필요합니다. Elasticserach의 사용자 이름과 패스워드를 지정해주어야 합니다.
도커에 Elasticsearch 컨테이너를 실행합니다.
Python
pip install elasticsearch ollama python-dotenv- Python Elasticserach 클라이언트를 이용해 벡터 데이터베이스를 요청을 수행합니다.
- dotenv에 패스워드 같은 민감한 정보와 Elasticserach의 정보를 저장했습니다.
# .env
EMBEDDING_MODEL="jeffh/intfloat-multilingual-e5-large-instruct:f16"
CHAT_MODEL="hf.co/heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF:Q5_K_M"
ES_URL="http://localhost:9200"
ES_USERNAME="elastic"
ES_PASSWORD="changeme"
ES_INDEX_NAME="vector1"- 임베딩 모델과 챗 모델을 허깅페이스에서 pull 받아 사용합니다.
- Elasticserach의 인덱스명은 vector1으로 지정했습니다.
Python 클라이언트와 Elasticserach 도커를 모두 구성했습니다. 이제 localhost:9200에 요청을 보내면 Elasticserach를 벡터 데이터베이스로 사용할 수 있습니다.
Example
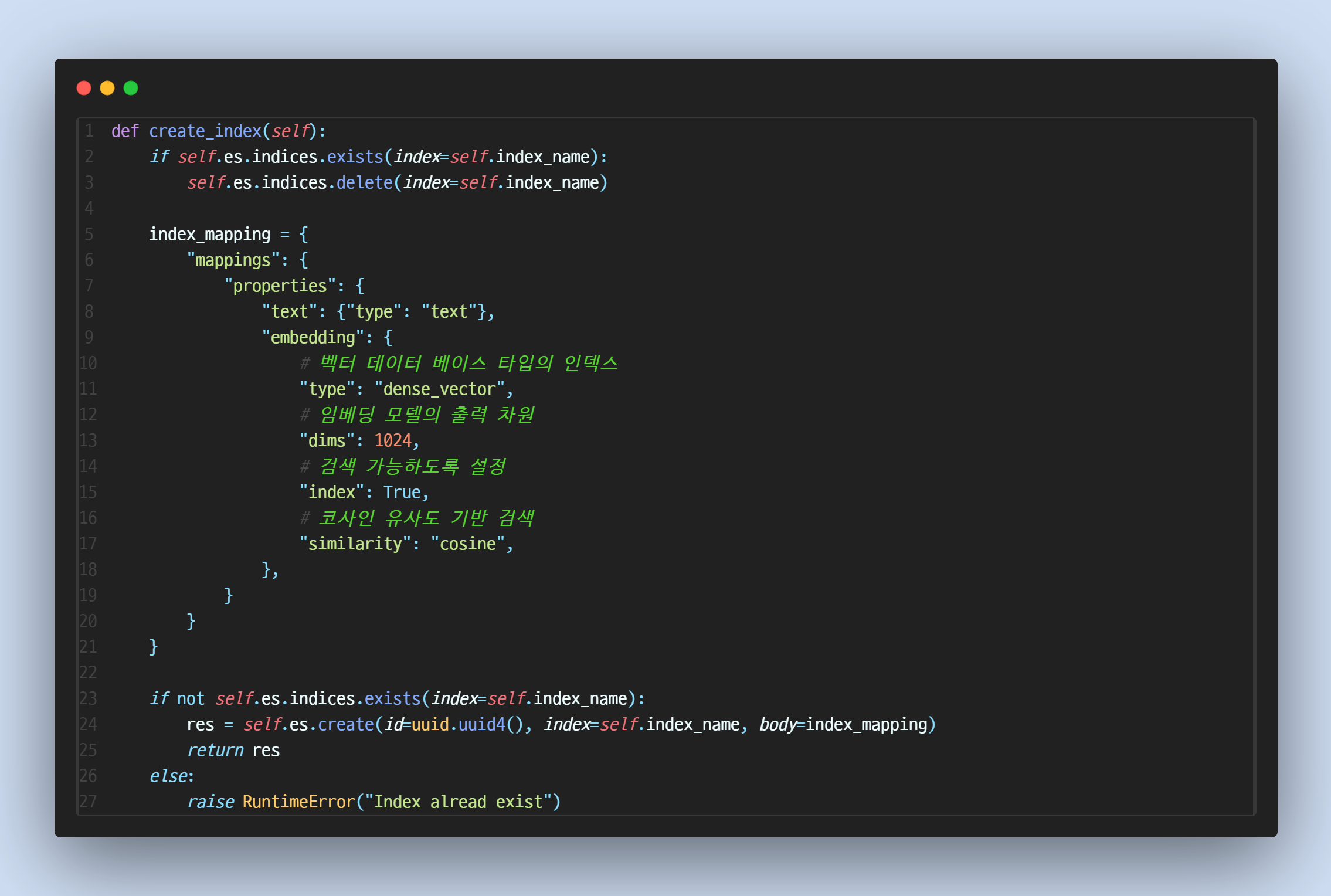
- 인덱스 생성
2. 문서 저장
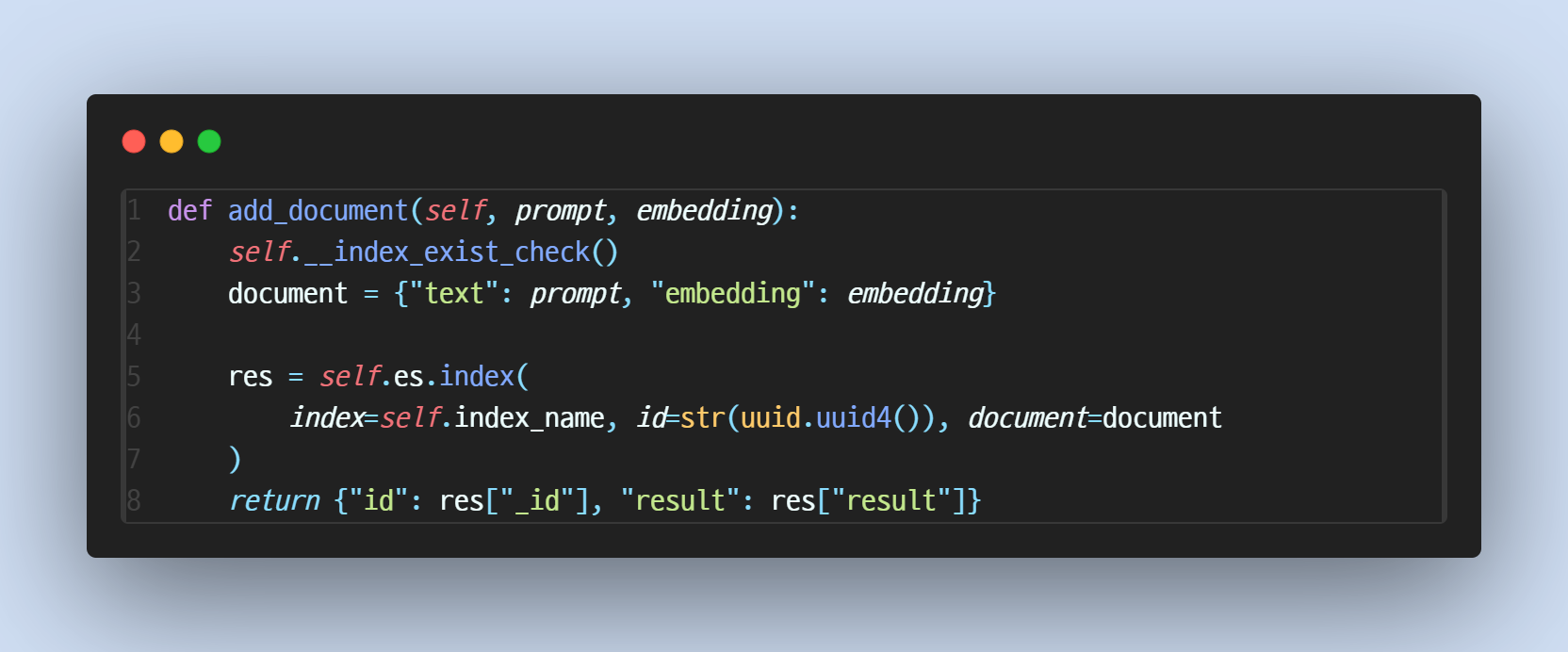
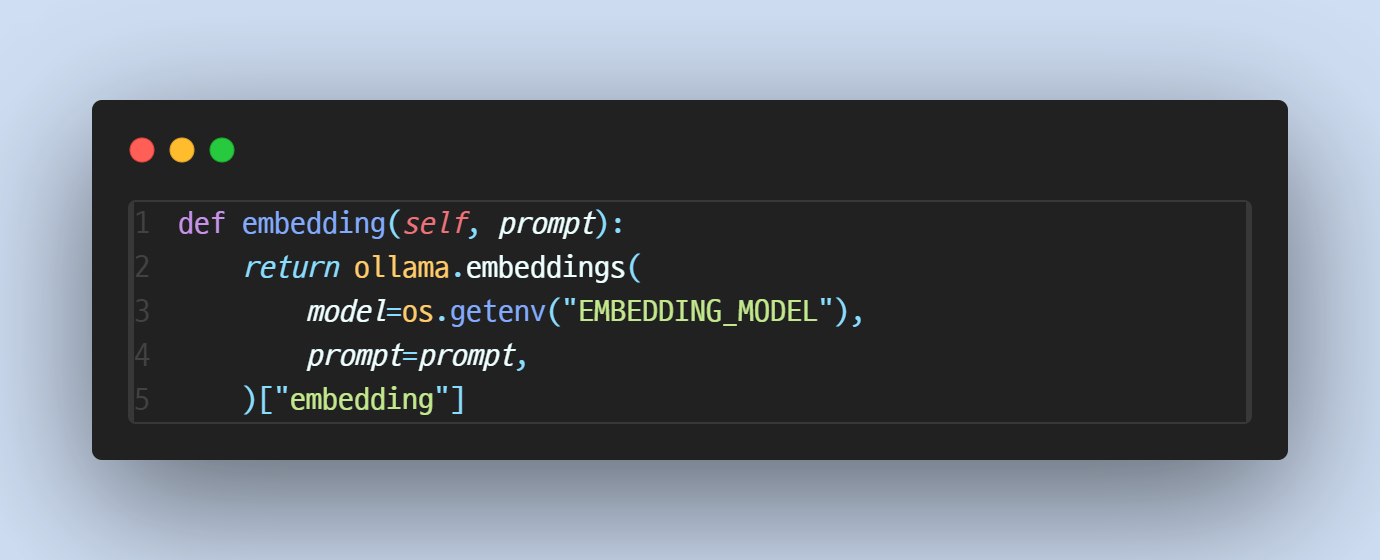
- embedding은 1024차원의 float 배열입니다. embedding을 생성하기 위해서는 ollama의 embedding 모델을 사용합니다.
3. 문서 검색
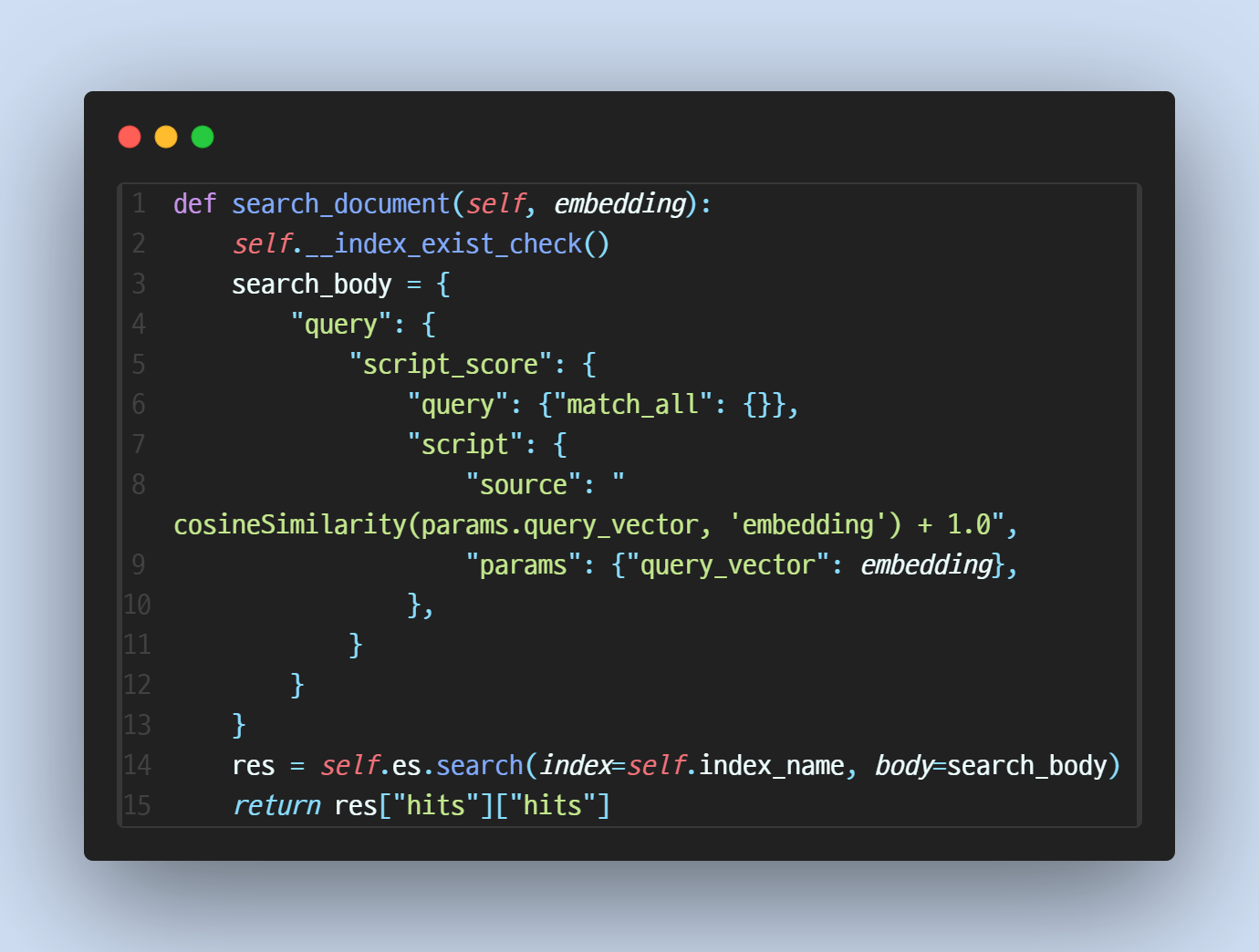
- 저장과 동일하게 embedding을 생성한 후 코사인 유사도를 이용해 유사 데이터를 검색합니다.
- 유사한 데이터가 없을 경우 빈 리스트([])가 반환됩니다.
이 글에서는 Python과 Elasticsearch를 이용해 벡터 데이터베이스를 구성하는 방법에 대해서 알아보았습니다. Elasticsearch는 검색에 있어서 높은 성능을 보여 널리 사용되고 있기 때문에 RAG 구현을 위한 벡터 데이터베이스로 구성했을 때 높은 안정성을 얻을 수 있습니다.
문의 02-6919-5516 | ✉ sales@bizspring.co.kr
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.