비즈스프링에서는 신속하고 정확한 광고 리포트를 제공하기 위해서 Elasticsearch를 사용하고 있습니다. 필요한 광고 데이터를 빠르게 검색하고 집계하여 보여주기 때문입니다. 이전 블로그 글에서는 Elasticsearch의 장점을 비즈스프링 솔루션에 어떻게 적용했는지 살펴보았다면, 이번에는 한 걸음 더 나아가 ES의 최적화된 운영과 유지보수 관점에서 데이터 관리 방안을 살펴보도록 하겠습니다.
비즈스프링이 Elasticsearch를 어떻게 활용하고 있는지 궁금하다면 , 아래 링크를 통해 확인하실 수 있습니다.
💾Elasticsearch -온라인 서비스를 위한 빅데이터 플랫폼
💾Elasticsearch를 사용한 AIR(매체통합리포트) 리포팅
💾AIR에서 Elasticsearch를 사용하기 위한 데이터 구성은 어떻게 할까
💾[AIR™] Elasticsearch 사용을 위한 쿼리 생성 과정
💾[AIR™] Elasticsearch를 사용한 리포트 생성하기
본론으로 들어가기에 앞서, Elasticsearch의 데이터 저장 방식과 구조에 대해 이해할 필요가 있습니다. Elasticsearch는 일반적인 DB와는 달리 역색인(inverted index) 개념을 활용하여 전문(Full-Context) 검색을 지원하며, 다음과 같은 장점을 제공합니다.
Elasticsearch 장점
1. REST 기반 인터페이스로 사용이 편리하고, JSON 형태의 데이터를 사용하므로 스키마에서 자유롭습니다. 즉, 정의한 데이터가 누락되어도 잘 작동하고, 정의하지 않은 데이터도 입력(인덱싱)이 가능합니다.
2. 분산처리(클러스터링)으로 대량의 데이터도 빠르게 처리합니다. Sharding에 따라 처리 속도를 높일 수 있으며, 데이터 노드를 추가하면 알아서 Shard를 재분배하여 최적의 성능을 내줍니다.
3. 실시간 데이터 처리가 가능합니다. 원천(Raw) 데이터 레벨에서 데이터 조회가 필요한 경우, 입력과 거의 동시에 바로 조회가 가능합니다.
엘라스틱의 데이터 구조
| Elasticsearch | 관계형 데이터베이스 | |
| 인덱스(Index) | 테이블(Table) | |
| 샤드(Shard) | 파티션(Partition) | |
| 문서 (Document) | 행 (Row) | |
| 매핑(Mapping) | 스키마 (Schema) | |
| Query DSL | SQL |
Index
Elasticsearch에서 Index란 하나의 논리적인 ‘저장 단위’입니다. RDBMS에서는 테이블(Table)과 유사한 개념이지만, RDBMS의 Index(검색 속도 향상을 위한)와는 다른 의미로 사용됩니다.
Elasticsearch는 분산 처리가 가능하여 여러 노드에 걸쳐 데이터를 저장할 수 있습니다. 이렇게 분산 저장된 데이터 묶음을 “Index”라는 논리적인 단위로 부릅니다. 하나의 물리 노드에 여러 개의 논리 인덱스를 생성하거나, 하나의 인덱스가 여러 노드에 분산 저장(M:N)되기도 합니다.
Shard
색인된 문서는 하나의 index-index 내부에 색인 된 데이터를 여러 개의 Partition으로 나뉘어 구성됩니다.
( Partition = Shard )
Type
인덱스 논리적 구조, 인덱스 당 하나의 타입만 설정이 가능합니다.
Document
Elasticsearch에서 데이터가 저장되는 최소 단위이며, RDBMS에서는 Row에 해당하는 개념이다. JSON Format으로 저장되어, 스키마 없이 데이터를 저장할 수 있으며 이는 자유로운 구조로 저장하는 것이 가능합니다.
Field
도큐먼트를 구성하는 속성이며, Document가 JSON 포맷으로 저장되기 때문에 Field는 Key:Value 포맷으로 저장되며, RDBMS와 비교하면 열(Column)에 해당하는 개념으로 볼 수 있습니다.
– 문서를 구성하기 위한 속성
– DB컬럼과 비교 가능
– 1개의 Field는 목적에 따라 다수의 데이터 타입을 가질 수 있다.
또한, REST API를 통해 아래와 같이 HTTP Method으로 호출되기도 합니다.
| ES HTTP Method | RDBMS SQL | |
| GET | SELECT | |
| PUT | INSERT | |
| POST | UPDATE, SELECT | |
| DELETE | DELETE | |
| HEAD (인덱스 정보확인) |
다음 예제에는 1의 document_id 가 할당된 bizspring 이라는 인덱스에 문서를 만드는 쿼리입니다. JSON 포맷으로 이루어져 실제 스키마가 존재하지 않더라도 데이터 삽입이 가능합니다.
POST /bizspring/_doc/1
{
"firstname": "Biz",
"lastname": "Spring"
}
Elasticsearch Index LifeCycle Management(ILM)
단순히 인덱스에 스케줄을 설정하는 것을 넘어 Shard 갯수 설정도 가능한 ILM은 해당 데이터 보관 상태에 따라서 4가지 상태로 나눌 수 있습니다. 적용 가능한 Policy의 예시는 아래와 같습니다.
- #Case.1 새로운 인덱스로 Roll-Over시, 최대 Size와 Age를 설정할 때
- #Case.2 가용성 (Availability)가 더 이상 중요치 않아 Replica를 줄여도 되는 시점을 설정할 때
- #Case.3 인덱스가 더 이상 Update 되지 않아 Primary Shards를 줄여도 되는 순간을 설정할 때
- #Case.4 언제 인덱스를 실제로 지울 것인지 설정할 때
예를 들어 광고 캠페인 데이터 중 랜딩 URL이 포함한 데이터에 ILM(LifeCycle Management)를 적용할 때 아래와 같은 정책을 적용할 수 있습니다.
- [1단계] 생성된 Index가 30GB에 도달하면 새로운 Index로 Roll-Over 수행
- [2단계] 오래된 Index 를 Hot -> Warm으로 바꾸고, Read-Only로 변경되며 1개의 Shards로 축소
- [3단계] 7일이 지나면 Index를 Warm -> Cold 단계로 전환하고 낮은 사양의 Spec Machine으로 이전
- [4단계] 30일의 보관기간을 넘으면 해당 Index를 삭제 처리
ILM 정책을 통해 Index 크기에 따라 Roll-Over1 기간, Doc 수량 또는 Doc의 보존 기간을 정의 할 수 있으며, 상대적으로 보관 공간이 작고 쓰기 작업이 적은 Hot-Warm 클러스터에서는 컴퓨팅 자원을 효율적으로 사용할 수 있기 때문에, 쿼리 요청 빈도가 많지 않은 데이터 관리에 적합한 방식입니다.
실제로 간단하게 엘라스틱 인덱스가 생성되는 틀이라고 할 수 있는 Template에 해당 ILM의 정책을 적용할 수 있습니다. 이는 Dev Tools 내의 Query를 통해 ILM 정책을 적용하거나, Kibana_UI에서도 생성하여 적용할 수 있습니다. 아래 [그림1]에서 그 과정을 확인하실 수 있습니다.
![[그림1] ILM Index Template 적용 사례](https://blog.bizspring.co.kr/wp-content/uploads/2024/12/그림3-2.jpg)
위의 그림은 Elasticsearch 내의 Kibana-UI를 통해서 Index LifeCycle Policy (ILM) 정책을 생성하는 과정을 보여줍니다. 해당 예제에서는 Index가 생성된 후, 1시간이 지나면 해당 Doc 내의 Data를 삭제하도록 설정해두었습니다.
이 ILM 정책은 적용된 시점 이후에 생성된 Index에만 반영됩니다. 적용된 정책은 [/Management/Elasticsearch/Index Lifecycle Management] 내의 Linked indices 항목에서 count가 되는 것으로 확인이 가능하며, Policy Options 내의 View indices linked to Policy를 통해 해당 Index의 삭제 모니터링을 확인할 수 있습니다.
Query로 해당 Index Template에 LifeCycle 정책이 반영되어 있는지 확인하는 방법은 아래와 같습니다.
GET _template/.monitoring-kibana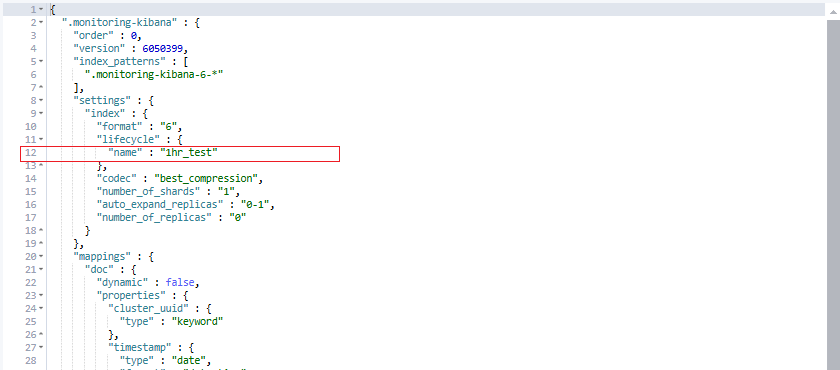
아래의 Query를 통해 적용 시점의 이후 Index( .monitoring-es-6-2024.12.17 ) 가 삭제됨을 확인 할 수 있습니다.
GET /_cat/indices/.monitoring-es-6*?v&s=index
#상태비교
green open .monitoring-es-6-2024.12.17 vtvrysQ2Q3KRT794krd1rA 1 1 184763 29898 210.8mb 106mb
green open .monitoring-es-6-2024.12.18 TcygaboLShiFcY1-cK1HKg 1 1 111997 19948 136.3mb 65.5mb
#상태비교
green open .monitoring-es-6-2024.12.10 foyuODG7RpSco1oRh1hk1A 1 1 6008292 44685 6.7gb 3.3gb
green open .monitoring-es-6-2024.12.18 TcygaboLShiFcY1-cK1HKg 1 1 202767 9970 413.1mb 205.9mb
위의 ILM을 적용하게 되면 Index 가 생성될 때에 해당 데이터를 언제까지 보관하고 관리할 것 인지를 설정하여, 시간과 리소스를 직접 사용하지 않더라도 설정된 정책을 통해 운영을 최적화 할 수 있습니다. ILM(LifeCycle Management)를 사용하여 효율적인 엘라스틱 클러스터 운영 방식을 이번 글로 나누어 보았습니다. 감사합니다.
References & Anotation
- https://www.elastic.co/guide/en/elasticsearch/reference/6.6/index-lifecycle-management.html
- 각 index의 사이즈 및 보관기간을 관리하는 위한 기능. 해당 미리 설정해 둔 값에 도달하면 기존 Index를 Rollover를 하고 새 Index에 쓴다. ↩︎