EXPLAIN 이란?
EXPLAIN은 어떻게 사용이 가능할까 ?
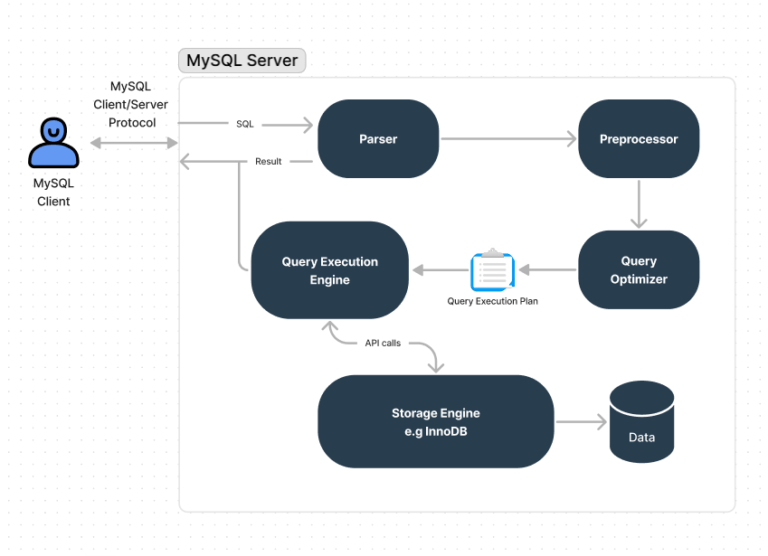
MySQL의 경우 쿼리를 실행 시, 각 테이블의 데이터 분포를 참조하여 가장 적은 비용으로 데이터를 조회하는데, 이 과정에서 데이터를 기반으로 실행 계획을 수립하는 쿼리 옵티마이저가 작동합니다.
EXPLAIN은 이 옵티마이저의 실행 계획을 표 형식으로 보여주는 기능입니다.
EXPLAIN 명령어의 사용법과 확인 가능한 정보
EXPLAIN
SELECT *
FROM employees e1
WHERE e1.emp_no IN (
SELECT e2.emp_no FROM employees e2 WHERE e2.first_name = ‘Matt’
UNION
SELECT e3.emp_no FROM employees e3 WHERE e3.last_name = ‘Matt’
)
ORDER BY birth_date DESC;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | e1 | ALL | 299,157 | 100 | Using where; Using filesort | |||||
| 2 | DEPENDENT SUBQUERY | e2 | eq_ref | PRIMARY | PRIMARY | 4 | func | 1 | 10 | Using where | |
| 3 | DEPENDENT UNION | e3 | eq_ref | PRIMARY | PRIMARY | 4 | func | 1 | 10 | Using where | |
| 4 | UNION RESULT | <union2,3> | ALL | Using temporary |
EXPLAIN 명령어를 실행하면 다음과 같이 결과가 출력됩니다.
각 항목에 대한 설명은 다음과 같습니다.
| 실행 계획 | 설명 |
|---|---|
| id | 실행 계획 결과의 ID 번호 |
| select type | SELECT 문의 유형 |
| table | 참조 테이블명 |
| partitions | 파티셔닝이 되어있을 경우 사용되는 필드명, 파티셔닝이 되어 있지 않을 경우 NULL |
| type | 해당 테이블 데이터의 접근 유형, 쿼리 튜닝에 가장 중요한 요소 중 하나 |
| possible_keys | 데이터 조회 시 사용 가능한 인덱스 필드 목록 |
| key | 실행에 사용할 기본 키 혹은 인덱스명, 없을 경우 NULL |
| key_len | 실제 사용할 기본 키 혹은 인덱스의 길이 |
| ref | Reference, 테이블 조인 시 어떤 조건으로 해당 테이블에 접근하는 지 |
| rows | 쿼리 실행 시 조회되는 데이터 수 |
| filtered | 이 쿼리로 실행 결과로 전체 데이터 중 필터링된 데이터의 비율 |
| Extra | MySQL 옵티마이저가 제공하는 힌트, 쿼리 튜닝에 가장 중요한 요소 중 하나 |
이 중 눈여겨 봐야할 항목인 type, Extra에 대해 살펴보겠습니다.
type
type은 해당 테이블에 있는 데이터에 접근하는 방식을 표시하는 필드입니다.
옵티마이저가 어떤 방법으로 row를 조회하는 지 나타내기 때문에 대상 테이블로 접근이 효율적인지 아닌지 판단을 할 수 있는 아주 중요한 항목입니다.
특히 접근 방식 중, ALL의 경우 쿼리에 사용되는 인덱스가 없어 모든 데이터를 탐색한다는 의미입니다.
모든 데이터를 탐색하기 때문에 시간이 다소 소요되고 쿼리 실행이 지연되는 주된 요인이 됩니다.
그러므로 인덱스 생성, 필터링을 통한 쿼리 튜닝의 주요 대상이 됩니다.
접근 방식은 다음과 같은 종류가 존재합니다. 상위에 위치한 항목일수록 속도가 빠릅니다.
| Type | 설명 |
|---|---|
| system | 테이블에 데이터가 1행 밖에 없는 경우 |
| const | 쿼리 결과가 1건을 반환, 가본 키 혹은 고유 키를 이용한 조건 필터링의 경우 |
| eq_ref | 조인(Join) 시 기본 키를 사용한 경우, 조인 단계에서 인덱스 혹은 기본 키로 필터링 하여 단 1건의 데이터를 조회할 경우 |
| ref | 조인 시 기본 키 혹은 고유 키가 아닌 인덱스를 사용한 경우 |
| ref_or_null | ref에서 NULL 비교가 추가된 형태 |
| index_merge | 여러 개의 인덱스가 동시에 사용되는 경우 |
| unique_subquery | 서브쿼리 접근에서 기본 키 혹은 고유 키를 사용하는 경우 |
| index_subquery | 서브쿼리 접근에서 인덱스를 사용하는 경우 |
| range | 인덱스를 하나의 값이 아닌 범위로 검색하는 경우, 성능 순위는 낮으나 해당 방법으로도 빠른 성능을 보장 |
| index | 인덱스를 처음부터 끝까지 조회하는 경우, all과 비슷한 형식이나 인덱스이기 때문에 all 보다는 효율적 |
| all | 테이블의 모든 데이터를 조회하는 경우, 가장 비효율적이므로 튜닝의 대상이 됨 |
Extra
Extra는 옵티마이저가 해당 쿼리를 어떻게 처리할 것인지에 대한 추가 정보를 보여줍니다.
이 정보를 통해 해당 쿼리가 실행될 때의 최적화 상태를 알 수 있어 쿼리 튜닝에 중요한 요소 중 하나입니다.
Extra 항목 중 Using temporary와 Using filesort의 경우 많은 비용이 필요하므로 쿼리 튜닝의 대상이 될 수 있습니다.
Extra의 여러 항목 중 주요 값들을 정리하면 다음과 같습니다.
| Extra | 의미 | 설명 |
|---|---|---|
| Using where | WHERE 조건 필터링 수행 | 인덱스가 아닌 필드로 필터링 |
| Using index | 커버링 인덱스 사용 | 테이블 데이터를 읽지 않고 인덱스만으로 쿼리를 처리함 |
| Using index condition | 인덱스 조건 푸시다운(Index Condition Pushdown) 사용 | 일부 WHERE 조건이 인덱스 수준에서 처리됨 |
| Using temporary | 임시 테이블 생성 | GROUP BY, DISTINCT, UNION, ORDER BY 등에서 중간 결과를 저장하기 위해 사용됨, 튜닝의 고려 대상이 됨 |
| Using filesort | 파일 정렬 수행 | 인덱스를 사용하지 않고 별도로 정렬 작업을 수행함, 튜닝의 고려 대상이 됨 (ORDER BY에서 주로 발생) |
| Range checked for each record | 각 레코드마다 범위 스캔을 시도 | 매우 비효율적이므로 튜닝의 대상 |
| Using join buffer (Block Nested Loop) | 조인 버퍼 사용 | 인덱스를 사용하지 못해 조인 시 메모리 버퍼를 사용함 |
| Using sort_union / union / intersect | 인덱스 조합 사용 | 여러 인덱스를 병합하여 결과를 도출함 |
| No tables used | 테이블 접근 없음 | 예: SELECT 1 같은 단순 계산 쿼리 |
EXPLAIN은 쿼리 튜닝을 시작할 때 가장 먼저 확인해야 하는 도구입니다.
실행 계획을 통해 MySQL이 데이터를 어떻게 처리하는지 파악하면, 인덱스 사용 여부나 조인 방식 등 성능 저하의 원인을 명확히 찾을 수 있습니다.
이러한 분석 과정을 거치면 감이 아닌 근거를 기반으로 쿼리 튜닝을 효율적으로 수행할 수 있습니다.
쿼리 최적화가 필요할 때는 EXPLAIN을 적극적으로 활용해 실행 계획을 검토해 보시길 권합니다.
Related Posts via Categories
- 분석 성능을 결정짓는 두 가지 : 데이터 웨어하우스와 모델링
- React에서 Apache Superset 사용하기
- GA4 이벤트 데이터를 실시간으로 확보하는 방법
- ChatGPT, Gemini도 못 찾는 당신의 콘텐츠: 구조화 데이터와 GEO의 역할
- 데이터 파이프라인 구조와 자동화 프로세스 한눈에 보기
- 엑셀 생성 라이브러리 비교: Apache POI vs xlsxwriter vs openpyxl
- 접근 제어 모델의 이해 : RBAC와 ABAC
- 높은 조회수가 관심이 아니라 ‘길을 잃은 신호’였던 이유 (고객 이탈 예측하기 2)
- 카프카가 정확히 뭔가요? 개념부터 클러스터 환경 구축까지 직접 해보기
- AEO를 넘어 GEO로: AI 마케팅, 무엇부터 시작해야 하는가?