RAG(Retrieval-Augmented Generation), 검색 증강 생성은 LLM 모델이 주어진 컨텍스트를 기반으로 텍스트를 생성하게 하는 방법입니다. 이를 통해 LLM 모델의 할루시네이션 문제를 어느정도 해결할 수 있습니다.
LLM 모델의 한계: 할루시네이션
Chat-gpt와 같은 LLM 모델은 우리의 일상 생활에 깊이 들어와 있습니다. 업무 뿐 아니라 일상적으로 사용하는 어플리케이션에도 AI가 사용되어 집니다.
하지만 이미 많은 분들이 겪은 것처럼, LLM 모델에는 할루시네이션이라는 한계점이 있습니다. 할루시네이션은 LLM 모델이 ‘모른다’라는 대답 대신 어떻게든 대답을 하기 위해 잘못된 정보를 생성하는 현상입니다.

LLM 모델이 발전됨에 따라서 위와 같은 터무니 없는 정보를 생성하는 현상은 사라졌지만, 여전히 복잡한 태스크를 요청할 경우 잘못된 정보를 생성하거나 똑같은 응답을 반복하는 현상을 보입니다.

이처럼 LLM 모델은 할루시네이션이라는 고질적인 한계를 가지고 있습니다. RAG은 LLM 모델에 컨텍스트를 부여해 응답의 정확도를 높이는 기법입니다.
RAG(Retrieval-Augmented Generation) : 검색 증강 생성
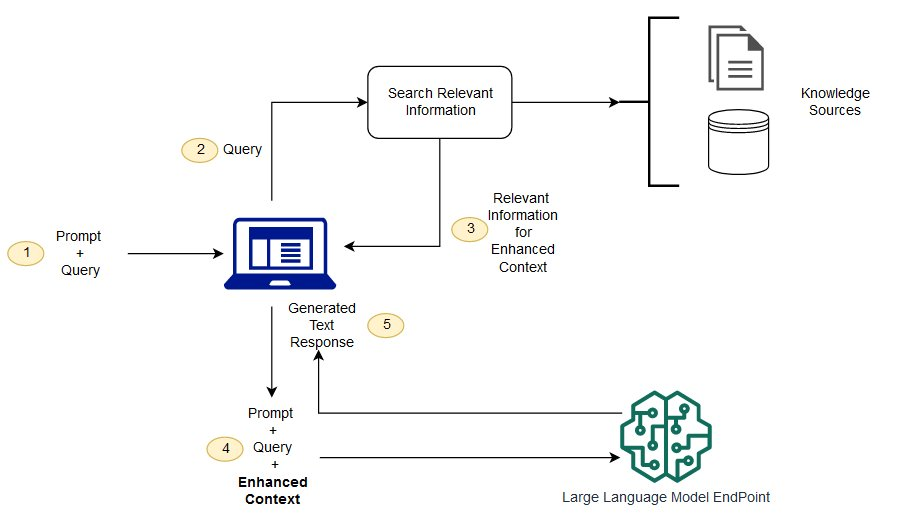
RAG은 LLM 모델에게 참고할 문서(데이터, db, Web 검색)를 주어 문서의 컨텍스트를 기반으로 응답을 하게 합니다. 위의 RAG은 다음과 같은 순서로 응답을 생성합니다.
- 사용자의 입력을 받아 쿼리를 분석
- 연관성이 높은 문서를 검색
- 연관된 문서를 바탕으로 응답을 생성
- 사용자에 응답
위 과정에서 컨텍스트에 사용되는 문서와 LLM 모델의 구성은 다양한 옵션들이 있습니다. 이번 아티클에서는 텍스트 기반의 문서와 Huggingface의 모델을 사용해 간단한 RAG 구현을 구현해 보겠습니다.
RAG Example
- 가상환경 구성 및 필요 라이브러리 설치
python -m venv .venv
. .venv/Scripts/activate
pip install transformers faiss-cpu dotenv
pip install torch torchvision torchaudio- 환경 변수 설정 / .env
KMP_DUPLICATE_LIB_OK=TRUE- 예시 문서 생성 / document.py
documents = [
"Seoul is the capital of South Korea and its largest city, with a population of over 9 million people.",
"It has been the capital for over 600 years, dating back to the Joseon Dynasty in 1394.",
"The city is home to UNESCO World Heritage Sites such as Changdeokgung Palace and Jongmyo Shrine.",
"Surrounded by mountains like Bukhansan, Seoul is a favorite spot for urban hikers."
]
- 검색기와 생성기를 각각 정의합니다.
# 검색
def get_embeddings(texts, model, tokenizer):
inputs = tokenizer(texts, return_tensors='pt',
padding=True, truncation=True)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.detach().numpy()
# Get Model
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Generate Embeddings, index
doc_embeddings = get_embeddings(documents, model, tokenizer)
index = faiss.IndexFlatL2(doc_embeddings.shape[1])
index.add(doc_embeddings)
# Searching function
def search(query, top_k=1):
embedding = get_embeddings([query], model, tokenizer)
D, I = index.search(embedding , top_k)
return [documents[i] for i in I[0]]
주어진 문서를 벡터화하고 faiss 라이브러리를 이용해 유사도를 분석합니다.
# 생성
gpt2_tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt2_model = GPT2LMHeadModel.from_pretrained('gpt2')
# Generating function
def generate_answer(query, context):
input_text = f"Context: {context}\n\nQuestion: {query}\n\nAnswer:"
inputs = gpt2_tokenizer.encode(input_text, return_tensors='pt')
outputs = gpt2_model.generate(
inputs, max_length=100, num_return_sequences=1)
return gpt2_tokenizer.decode(outputs[0], skip_special_tokens=True)
유사한 문서를 컨텍스트로 사용해 응답을 생성합니다.
- RAG 실행
load_dotenv()
# 사용자 질문
query = "Where's capital of Korea?"
# 관련 문서 검색
retrieved_docs = search(query, top_k=1)
context = retrieved_docs[0]
# 답변 생성
answer = generate_answer(query, context)
print(f"Question: {query}")
print(f"Answer: {answer}")
- 응답 결과
Question: Where's capital of Korea?
Answer: Context: Seoul is the capital of South Korea and its largest city, with a population of over 9 million people.
주어진 문서 중 첫 번째 문장을 활용해 서울이 한국의 수도라는 응답을 얻었습니다. (사용된 베이스 모델이 gpt-2인 점, 문서가 빈약한 문제로 질문에 따라 엉뚱한 응답이 생성될 수 있습니다.)
결론
RAG은 LLM 모델의 한계점인 할루시네이션을 보완하기 위해 LLM 모델이 컨텍스트로 사용할 수 있는 문서를 제공해 정확도를 높이는 기법입니다. 이번 아티클에서는 RAG의 정의와 간단한 예시 코드를 작성해 보았습니다.
다음 아티클에서는 LangChain을 활용한 RAG 기법과, RAG을 사용할 때 유의할 사항들에 대해 알아보겠습니다.
[References]
- https://blog.deeplink.kr/?p=3478
- https://hi-lu.tistory.com/entry/%EC%99%95%EC%B4%88%EB%B3%B4%EC%9A%A9-langchain-%EC%BD%94%EB%93%9C-%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC-w-RAG
- https://blog.naver.com/htk1019/223423287480