오늘날 우리는 데이터가 중심이 되는 세상에 살고 있습니다. 다양한 산업 분야에서 데이터는 기업과 개인의 의사결정을 이끄는 중요한 자산으로 자리 잡았습니다. 특히 데이터가 생성되는 즉시 이를 활용해야 하는 실시간 데이터 처리의 중요성이 주목받고 있으며, 이는 단순히 데이터를 저장하고 분석하는 단계를 넘어 새로운 혁신의 중심에 있습니다.
실시간 데이터는 빠르게 변화하는 시장 환경에 적응하고, 고객 경험을 개인화하며, 효율적인 시스템을 구축하는데 필수적인 역할을 합니다. 이러한 요구에 부응하기 위해 Apache Kafka Streams는 실시간 데이터 처리와 분석을 지원하는 강력한 도구로 떠오르고 있습니다. 이번 글에서는 Kafka Streams가 어떻게 데이터 처리의 패러다임을 변화시키고 있는지, 주요 특징과 활용 사례를 통해 그 혁신적인 역할을 살펴보고자 합니다.
데이터 분석의 변화와 실시간 데이터의 중요성
데이터 처리 기술은 시간이 지나면서 점진적으로 발전하며 데이터의 양과 속도, 복잡성에 대응하는 방향으로 변화해 왔습니다. 초기에는 처리해야 할 데이터의 양이 적어, 주로 간단한 일괄 처리(batch processing)가 사용되었습니다. 이후 클라우드 서비스의 확산과 더불어 소셜 네트워크 서비스(SNS), 전자거래, 스트리밍 서비스, 사물인터넷(IoT) 기기 등 다양한 플랫폼에서 대량의 데이터가 지속적으로 생성되면서 본격적인 빅데이터 시대가 도래했습니다. 이러한 환경에서는 데이터를 저장하고 나중에 분석하는 기존 방식으로는 즉각적인 대응이 쉽지 않기 때문에, 데이터를 실시간으로 처리하고 활용하는 기술이 중요해졌습니다.
실시간 데이터(real-time data)는 생성되는 즉시 처리되어 의사결정과 서비스 제공에 즉각적으로 활용할 수 있는 데이터를 의미합니다. 이는 단순히 데이터를 저장하거나 분석하는 것을 넘어, 빠르게 변화하는 시장 상황에 신속하게 대응하고, 사용자 경험을 개인화하는 데 핵심적인 요소가 되었습니다. 예를 들어 물류 시스템에서 실시간 배송 추적 기능을 제공하거나, 웨어러블 기기에서 수집된 심박수, 혈압 등의 데이터를 분석해 건강 상태를 실시간으로 모니터링하는 등 일상 속에서 실시간 데이터의 중요성은 더 뚜렷해지고 있습니다.
Kafka Streams 소개
웹 애플리케이션 분야에서는 Google Dataflow, RabbitMQ Streams, Azure Stream Analytics 등 실시간 데이터 처리를 위한 여러 라이브러리 및 서비스가 존재하는데요, 대중적으로 Apache Kafka에서 제공하는 Kafka Streams 라이브러리가 많이 사용됩니다. Kafka Streams는 분산형 스트림 처리 라이브러리입니다. Kafka의 데이터를 활용해 실시간으로 데이터를 처리하고 분석할 수 있는 애플리케이션을 손쉽게 개발할 수 있도록 설계되었습니다. 주요 특징 및 장점은 다음과 같습니다.
- 경량 클라이언트 라이브러리입니다.
- Kafka Streams는 단순하고 가벼운 라이브러리로, Java 애플리케이션에 손쉽게 임베드 할 수 있습니다.
- 사용자의 애플리케이션 배포 및 운영 도구와 손쉽게 통합할 수 있습니다.
- 외부 의존성이 없습니다.
- Apache Kafka 자체를 내부 메시징 계층으로 사용하는 것 외에는 외부 시스템에 대한 의존성이 없습니다.
- Kafka의 파티셔닝 모델을 용하여 수평 확장성과 강력한 메시지 순서를 보장합니다.
- 상태 관리 및 실시간 질의를 제공합니다.
- 장애 허용 로컬 상태 저장소(fault-tolerant local state)를 활용해 빠르고 효율적인 상태 기반 연산(집계, 윈도우 조인 등)을 지원합니다.
- 장애가 발생해도 상태 저장소를 통해 데이터를 안전하게 복구할 수 있습니다.
- Exactly-Once 처리 보장
- 메시지를 중복 처리하거나 누락 없이 정확히 한 번만 처리(Exactly-once)하는 것을 보장합니다.
- Kafka Streams는 스트림 클라이언트와 Kafka 브로커 간의 장애가 발생해도 데이터 일관성을 유지합니다.
- 밀리초 단위의 처리 지연
- 레코드 단위 처리를 통해 밀리초 단위의 지연(latency)으로 실시간 데이터 스트림 처리를 지원합니다.
- 이벤트 시간 기반 윈도우 연산과 순서 없는 데이터 처리(out-of-order records)도 효과적으로 관리합니다.
- 필요한 스트림 처리 기본 요소 제공
- 고수준의 Streams DSL과 저수준의 Processor API를 함께 제공하여 다양한 스트림 처리 요구사항에 대응할 수 있습니다.
Kafka Streams 구성 요소
Kafka Streams의 다양한 특징과 장점에 대해서 알아봤는데요, 이번에는 핵심 구성 요소를 알아보겠습니다.
Kafka Streams에서 가장 자주 언급되는 단어는 ‘스트림’입니다. 스트림(Stream)이란 Kafka Streams의 핵심 추상화로, 순서가 보장된 불변 데이터 레코드(key-value pair)의 연속적인 집합을 의미합니다. 이 스트림은 실시간으로 업데이트 되며, 재생 가능(replayable)하고, 장애 허용(fault-tolerant)이라는 특징을 가집니다.
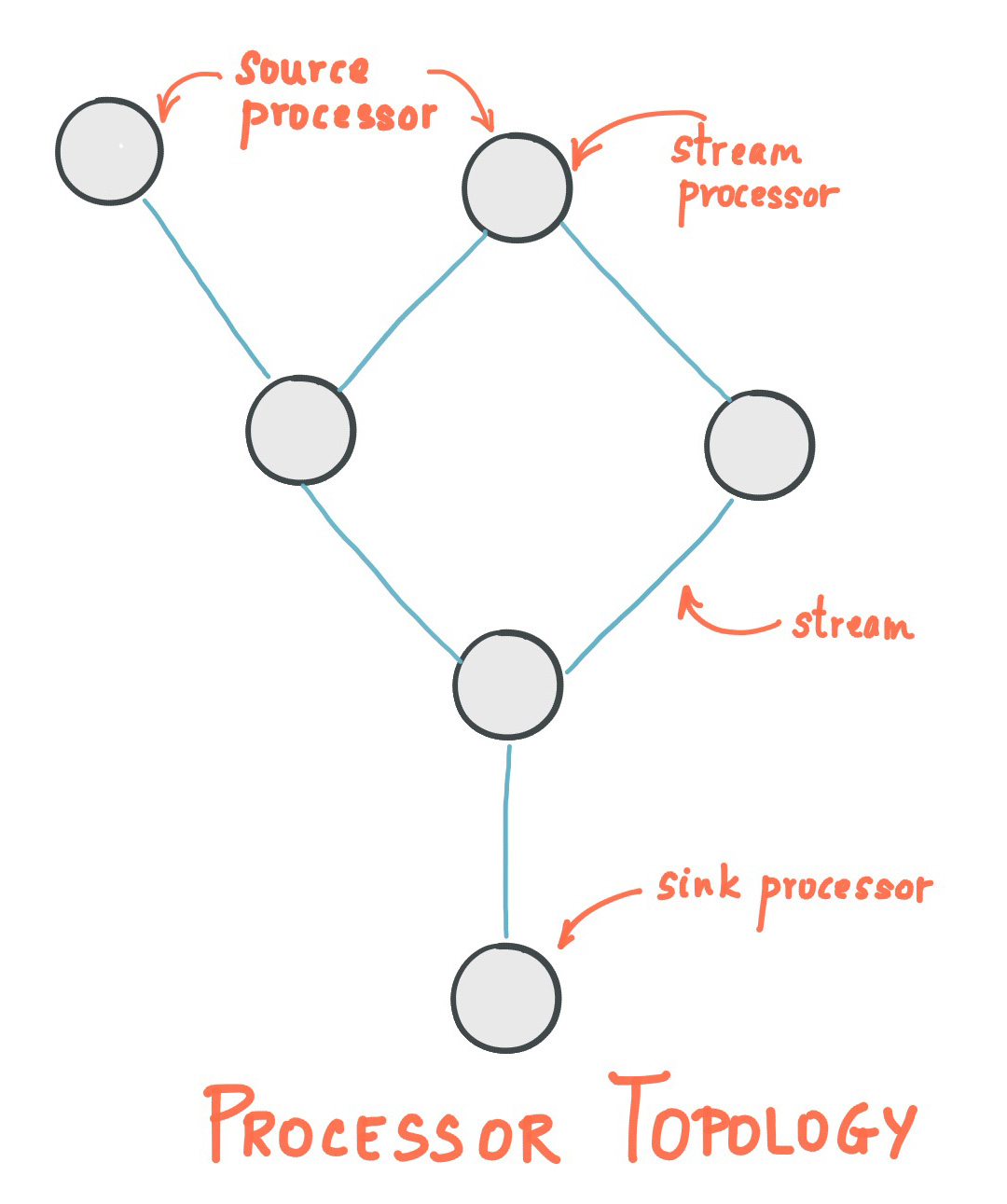
Kafka Streams는 데이터를 처리하는 노드(Processor)와 이를 연결하는 선(stream)으로 구성된 그래프 형태의 프로세서 토폴로지를 정의합니다. Source Processor가 Kafka 토픽(topic)으로부터 데이터를 가져오면 Stream Processor가 데이터에 대한 처리를 진행하고, 처리된 데이터는 Sink Processor가 토픽에 저장됩니다. 이런 구조는 Streams DSL, Processor API로 구현할 수 있습니다.
토픽(Topic)이란?
데이터를 논리적으로 분류하고 저장하는 단위로, 메시지 데이터의 생산자와 소비자가 데이터를 교환하는 기본 단위입니다.
활용 사례
Kafka Streams는 다양한 산업 분야에서 실시간 데이터 처리를 가능하게 하여 기업들이 신속하고 효율적인 의사 결정을 내릴 수 있도록 지원합니다. 아래는 일반적인 산업 분야에서의 활용 예시와 대표적인 기업들의 도입 사례입니다.
우선 일반적인 산업 분야에서 Kafka Streams를 어떻게 사용하는지 간략히 알아보겠습니다.
- 금융 서비스: 금융 기관들은 Kafka Streams를 활용하여 실시간 거래 모니터링과 사기 탐지를 수행합니다. 이를 통해 이상 거래를 신속하게 감지하고 대응할 수 있습니다.
- 전자 상거래: 온라인 쇼핑몰에서는 사용자 행동 데이터를 분석하여 개인화 된 추천 시스템을 구축합니다. Kafka Streams를 통해 실시간으로 사용자 활동을 처리하고 맞춤형 상품 추천을 제공합니다.
- 소셜 미디어: SNS 플랫폼들은 사용자 활동 스트림을 처리하여 실시간 피드 업데이트, 알림, 트렌드 분석 등을 실행합니다.
- 사물인터넷(IoT): 센서 네트워크에서 수집된 데이터를 실시간으로 처리하여 상태 모니터링, 예측 유지보수, 이상 감지 등을 구현합니다.
- 헬스케어: 환자 모니터링 시스템에서 실시간으로 생체 신호를 분석하여 응급 상황을 감지하고 즉각적인 대응을 가능하게 합니다.
다음으로는 대표적인 기업들의 도입 사례를 살펴보겠습니다.
라인 (LINE)
라인은 데이터 파이프라인 효율화를 위해 Kafka Streams를 도입했습니다. 기존 Apache Samza의 복잡성과 YARN 의존성 문제를 극복하기 위해 Kafka Streams를 선택했으며, 이 라이브러리의 가벼운 실행 모델과 강력한 DSL을 활용해 사내 시스템 간 이벤트 전달과 백그라운드 태스크 처리를 통합했습니다. Kafka Streams 기반으로 Loopback Replicator를 구현해 토픽 데이터를 분류하고, Decaton으로 기존 태스크 큐의 확장성과 신뢰성을 개선했습니다. 이를 통해 서비스 성능을 유지하며 안정적인 데이터 처리 환경을 구축했습니다.
오늘의집
오늘의집은 광고 정산 시스템을 구축하면서 Kafka Streams를 도입했습니다. 기존 RDB를 이용한 정산 시스템에서 발생한 중복 차감, 복잡한 로직, 데이터 저장소 관리 문제를 해결하기 위해 Kafka Streams를 활용했습니다. exactly-once 처리 보장과 Kafka Transaction을 통해 중복 처리 없이 안정적인 정산 작업을 구현하였으며, in-memory DB와 Kafka topic을 결합하여 데이터 손실을 방지하고 복구 기능을 제공했습니다. 이를 통해 실시간 예산 조회와 높은 처리량을 달성하고, 클릭 통계를 효율적으로 관리하며 향후 요구사항 변경에도 유연하게 대응할 수 있는 구조를 마련했습니다.
우아한 형제들
우아한형제들은 배치 방식의 한계(지연, 처리 시간 예측 어려움)를 극복하기 위해 Kafka Streams를 도입했습니다. Kafka Streams는 별도의 클러스터 없이 실시간 스트림 처리와 상태 저장소(State Store)를 활용한 데이터 관리가 가능하여, 라이더의 GPS 데이터를 행정동 단위로 집계하고 조회하는 시스템을 구현했습니다. 장애 발생 시 복구와 효율적인 파티션 관리로 안정적인 데이터 처리를 보장하며, 실시간 데이터 흐름을 기반으로 이상 탐지와 상황 파악이 가능해졌습니다.
이처럼 Kafka Streams는 다양한 산업에서 실시간 데이터 처리를 위한 강력한 도구로 자리 잡고 있습니다. 단순한 데이터 분석을 넘어 변화하는 시장 상황에 신속히 대응하고, 서비스 성능을 높이며, 사용자 경험을 개인화하는 데 중요한 역할을 하고 있습니다. 앞으로도 Kafka Streams는 실시간 데이터 활용을 극대화하려는 기업들에게 필수적인 선택지로 계속 주목받을 것이며, 이를 통해 데이터 중심의 혁신과 효율적인 시스템 구축이 더욱 가속화될 것으로 기대됩니다.
Reference
https://kafka.apache.org/39/documentation/streams/core-concepts
https://engineering.linecorp.com/ko/blog/applying-kafka-streams-for-internal-message-delivery-pipeline
https://www.bucketplace.com/post/2022-05-20-%EA%B4%91%EA%B3%A0-%EC%A0%95%EC%82%B0-%EC%8B%9C%EC%8A%A4%ED%85%9C%EC%97%90-kafka-streams-%EB%8F%84%EC%9E%85%ED%95%98%EA%B8%B0/
https://www.youtube.com/watch?v=YACC1t_oSlA