“데이터만 충분히 쌓이면 언젠가 분석도 쉬워질 것”이라고 생각해본 적 있으신가요?
하지만 막상 데이터를 뽑아보려 하면 쿼리가 끝없이 길어지거나 테이블 간의 복잡한 관계를 이해하느라 시간을 허비하게 됩니다.
이는 좋은 집(데이터 웨어하우스)을 짓는 것만큼, 그 안에 가구(데이터)를 어떻게 배치할지 설계하는 ‘데이터 모델링’이 중요한 이유이기도 합니다. 오늘은 데이터 분석 플랫폼의 성패를 좌우하는 핵심 개념 두 가지를 살펴보려 합니다.
데이터는 많은데 왜 분석은 어려울까?
대부분의 기업은 서비스 운영을 위해 다양한 시스템을 사용합니다.
- 사용자 행동 데이터 : 서비스 DB
- 매출 데이터 : 결제 시스템
- 광고 성과 데이터 : 마케팅 플랫폼
- 고객 데이터 : CRM 시스템
- 주문 시스템 : 주문 시스템
문제는 이 데이터들이 각기 다른 구조로 흩어져 있다는 점입니다. 운영 시스템의 최우선 가치는 빠른 처리와 무결성이기 때문이죠. 하지만 분석 관점에서는 다음과 같은 고충이 발생합니다.
- 팀마다 지표를 계산하는 기준이 달라 숫자가 맞지 않음
- 분석 쿼리가 너무 복잡해져 실수할 확률이 높음
- 데이터를 찾는 시간이 실제 분석 시간보다 길어짐
이 문제를 해결하기 위해 등장한 개념이 바로 데이터 웨어하우스(Data Warehouse)입니다.
데이터 웨어하우스(Data Warehouse)란?
데이터 웨어하우스는 기업 내 여러 시스템에서 생성되는 데이터를 한 곳에 모아 분석하기 쉽게 저장한 중앙 데이터 저장소입니다.
쉽게 말하면 “분석과 의사결정을 위해 데이터를 모아 정리해 둔 데이터 창고”라고 볼 수 있습니다.
비유하자면 다음과 같습니다.
DW = 물류 창고 : 제품을 종류별로 분류하고 정리하여 찾기 쉽게 진열해 둔 곳
운영 DB = 공장 : 제품(데이터)이 쉴 새 없이 생산되는 곳
공장에서는 제품이 계속 생산됩니다.
하지만 제품을 바로 찾기 쉽도록 하려면 물류 창고에서 정리하고 분류해야 합니다.
데이터도 마찬가지입니다.
서비스에서 생성된 데이터는 그대로 두면 분석하기 어렵기 때문에 분석에 적합한 형태로 정리해 모아두는 공간이 필요합니다.
데이터 웨어하우스의 기본 구조
일반적인 데이터 흐름은 다음과 같습니다.
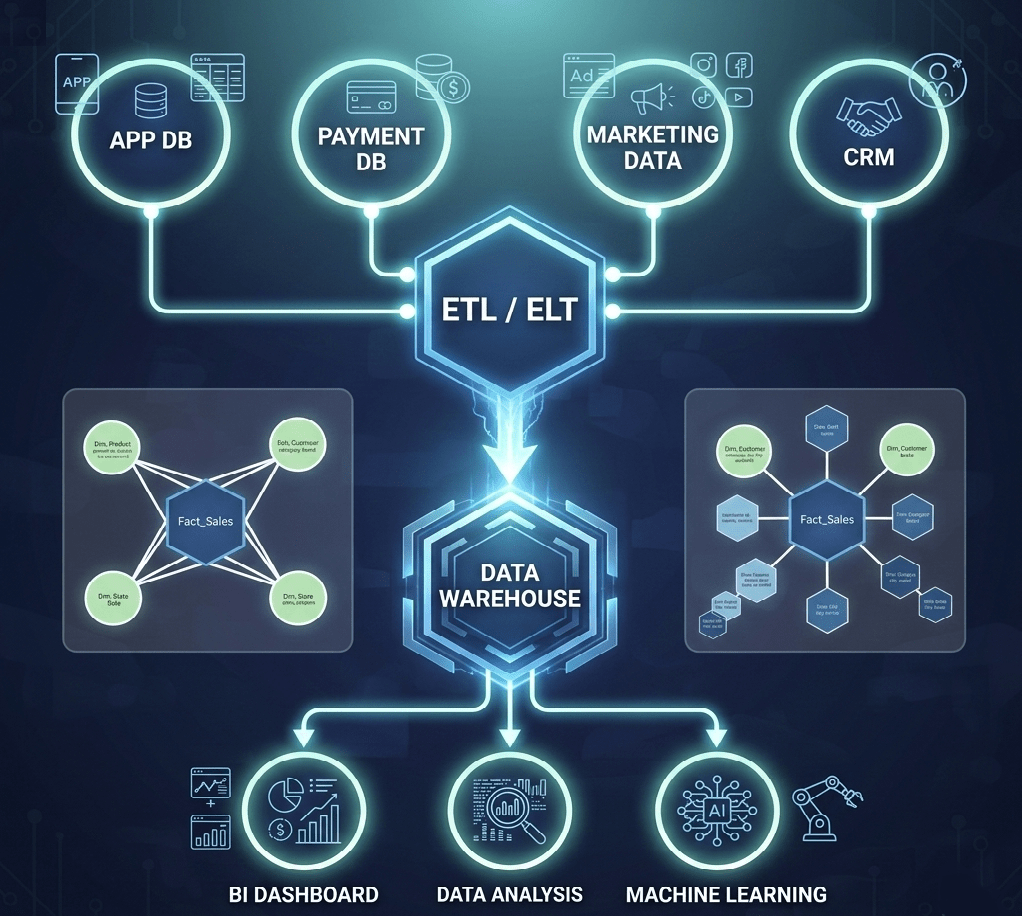
데이터 웨어하우스에서는 보통 다음과 같은 작업이 이루어집니다.
- Extract : 여러 시스템에서 데이터 수집
- Transform : 데이터를 정제하고 변환
- Load : 분석하기 좋은 형태로 저장
이 과정을 흔히 ETL (Extract, Transform, Load)이라고 부릅니다.
하지만 ETL을 통해 데이터를 한 곳에 모았다고 해서 자동으로 분석이 쉬워지는 것은 아닙니다. 데이터를 어떤 구조로 설계하느냐가 더 중요합니다.
데이터 웨어하우스의 주요 특징
1) 분석 중심 데이터 구조
- 운영 DB와 달리 분석을 위한 구조로 설계
- 예 : 스타 스키마, 스노우플레이크 스키마
2) 다양한 데이터 통합
- 여러 시스템의 데이터를 하나의 기준으로 통합
- 예 : 고객 ID 통합, 매출 지표 통합, 날짜 기준 통일
3) 대규모 데이터 처리
- 데이터 웨어하우스는 보통 수십 GB ~ 수 PB 이상의 데이터를 처리
- 대표적인 클라우드 DW : Google BigQuery, Snowflake, Amazon Redshift
운영 DB vs 데이터 웨어하우스
| 구분 | 운영 DB | 데이터 웨어하우스 |
|---|---|---|
| 목적 | 서비스 운영 | 데이터 분석 |
| 데이터 구조 | 정규화 중심 | 분석 중심 |
| 쿼리 | 트랜잭션 처리 | 대규모 분석 |
| 사용자 | 백엔드 시스템 | 데이터 분석가 / BI |
데이터 모델링(Data Modeling)이란?
데이터 모델링은 현실의 비즈니스 구조를 데이터 형태로 정리하고 설계하는 과정입니다.
쉽게 말하면 “데이터를 이해하고 분석하기 쉽도록 구조를 설계하는 작업”입니다.
마치 건물을 짓기 전에 설계도를 그리는 것과 같습니다. 이 설계도가 튼튼해야 데이터 분석가가 원하는 데이터를 빠르게 찾고, 복잡한 비즈니스 질문에 답할 수 있습니다.
그래서 데이터를 어떤 테이블에 저장할지, 어떤 관계로 연결할지, 어떤 기준으로 정리할지를 미리 설계해야 합니다.
데이터 모델링의 세 가지 종류
건물 설계에 단계가 있듯 데이터 모델링도 추상화 수준에 따라 세 가지로 나뉩니다.
1) 개념적 데이터 모델링(Conceptual)
무엇(What)을 데이터로 만들 것인가를 결정하는 가장 높은 수준의 단계
- 목적 : 비즈니스의 핵심 엔티티(대상)와 그들 간의 관계를 파악
- 특징 : 상세한 속성(이름, 나이 등)보다는 큰 덩어리 위주로 설계합니다. (예: 고객 – 주문 – 상품)
2) 논리적 데이터 모델링(Logical)
어떻게(How) 구성할 것인가를 결정하며 비즈니스 규칙을 상세하게 정의하는 단계
- 목적 : 각 엔티티의 모든 속성(Attribute), 식별자(PK), 관계를 구체화하고 정규화를 수행
- 특징 : 특정 데이터베이스 제품(Oracle, MySQL 등)에 종속되지 않는 독립적인 설계
3) 물리적 데이터 모델링(Physical)
어디(Where)에 어떤 성능으로 저장할 것인가를 결정하는 실행 단계
- 목적 : 실제 DBMS(PostgreSQL, BigQuery 등)의 특성에 맞춰 테이블명, 컬럼 타입, 인덱스, 파티셔닝 등을 설정
- 특징 : 성능 최적화를 위해 의도적으로 정규화를 깨트리는 비정규화를 수행
데이터 모델링 설계의 3단계 핵심 요소
데이터 모델링은 단순히 테이블을 만드는 것이 아니라, 비즈니스의 규칙을 데이터 구조로 변환하는 과정입니다.
1) 엔티티(Entity) 설계 : “무엇을 관리할 것인가?”
데이터로 관리해야 할 실체(대상)를 정의합니다.
- 핵심 엔티티 : 고객, 상품, 주문, 매장 등 비즈니스의 주인공들
- 속성(Attribute) : 각 엔티티가 가지는 세부 정보 (예: 고객명, 연락처, 가입일, 상품가격 등)
- 식별자(Primary Key) : 각 데이터를 유일하게 구분할 수 있는 고유값 (예: 고객번호, 주문ID)
2) 관계(Relationship) 설계 : “데이터끼리 어떻게 연결되는가?”
엔티티 간의 비즈니스적 연관성을 정의합니다.
- 관계의 종류: * 1:1 (일대일): 한 명의 고객이 하나의 프로필만 가짐
- 1:N (일대다) : 한 명의 고객이 여러 번 주문을 함. (가장 흔한 형태)
- N:M (다대다) : 여러 학생이 여러 과목을 수강함. (설계 시 1:N 관계로 풀어내는 과정이 필요)
- 외래키(Foreign Key) : 다른 테이블의 정보를 참조하기 위한 연결 고리 설정
3) 제약 조건(Constraint) 설계 : “데이터의 품질을 어떻게 지킬 것인가?”
데이터가 오염되지 않도록 규칙을 세웁니다.
- Not Null : 필수 입력 항목 설정 (예: 주문 시 결제 금액은 비어있으면 안 됨)
- Unique : 중복 방지 (예: 이메일 주소 중복 가입 불가)
- Check : 값의 범위 제한 (예: 수량은 0보다 커야 함)
데이터 웨어하우스 환경에서는 이러한 모델링을 분석 중심 구조로 설계하는 것이 일반적입니다.
그 대표적인 방식이 바로 스타 스키마와 스노우플레이크 스키마입니다.
대표적인 데이터 모델링 방법 : 스타 스키마 vs 스노우플레이크
데이터 웨어하우스(DW) 설계에서 가장 많이 마주하는 두 가지 모델, 스타 스키마(Star Schema)와 스노우플레이크(Snowflake Schema)를 비교해 보겠습니다.
스타 스키마 (Star Schema)
중심에 팩트 테이블(Fact Table)이 있고, 이를 여러 디멘션 테이블(Dimension Table)이 둘러싸고 있는 형태입니다.
BI 대시보드나 데이터 분석에서 가장 많이 사용됩니다.
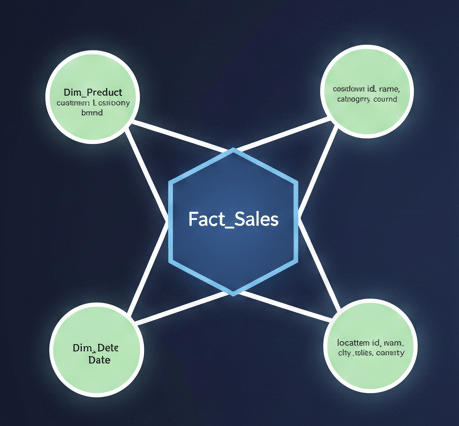
1) 구성
중앙의 Fact 테이블과 주변의 Dimension 테이블 구조
Fact 테이블은 비즈니스 이벤트와 측정값 저장하고 Dimension 테이블은 분석 기준 정보 저장
dim_date
|
dim_user — fact_sales — dim_product
|
dim_channel2) 특징
- 비정규화 구조 : Dimension 테이블이 정규화되지 않고 하나의 테이블에 많은 정보가 포함
dim_product
product_id
product_name
category_name
brand_name
department_name- 쿼리가 단순 : 조인 횟수가 적어서 이해하기 쉬움
SELECT
d.month,
p.category,
SUM(f.sales_amount)
FROM fact_sales f
JOIN dim_date d
ON f.date_id = d.date_id
JOIN dim_product p
ON f.product_id = p.product_id
GROUP BY 1,23) 장점 : 구조가 단순하여 이해하기 쉽고, 조인(Join) 횟수가 적어 쿼리 속도가 빠름
4) 단점 : 디멘션 테이블에 데이터 중복이 발생(비정규화)
스노우플레이크 스키마 (Snowflake Schema)
스타 스키마의 디멘션 테이블을 정규화하여 뻗어나가게 만든 구조입니다. 별(Star)의 가지 끝에 또 가지가 달린 눈송이(Snowflake) 모양과 같다고 해서 붙여진 이름입니다.
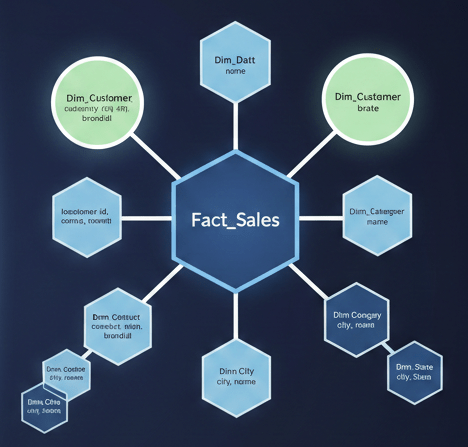
1) 구성
Dimension을 정규화해서 여러 테이블로 분리
Fact 테이블은 스타 스키마와 동일하고 Dimension 테이블은 스타스키마에서는 하나였던 dimension이 여러 테이블로 나뉨
dim_date
|
dim_user — fact_sales — dim_product
|
dim_category
|
dim_department2) 특징
- 정규화된 구조 : 차원 테이블을 여러 테이블로 분리
dim_product
product_id
product_name
category_id
dim_category
category_id
category_name
department_id
dim_department
department_id
department_name- 조인 증가 : 분석할 때 더 많은 조인 필요
fact_sales
JOIN dim_product
JOIN dim_category
JOIN dim_department3) 장점 : 데이터 중복이 제거되어 데이터 무결성 유지에 유리하고 저장 공간을 절약
4) 단점 : 쿼리 시 많은 테이블을 조인해야 하므로 복잡도가 높고 성능이 저하
결국 데이터 플랫폼 설계는 단순히 기술 도구를 도입하는 것을 넘어 ‘우리 비즈니스의 흐름을 어떻게 가장 이해하기 쉬운 데이터 구조로 표현할 것인가’를 고민하는 일입니다.
오늘 소개한 데이터 웨어하우스와 데이터 모델링 개념이 여러분의 데이터 환경을 조금 더 명확하게 설계하는 데 도움이 되길 바랍니다.
최신 마케팅/고객 데이터 활용 사례를 받아보실 수 있습니다.